Content
The 12 Best Speech to Text Software Tools in 2025 (Ranked)
The 12 Best Speech to Text Software Tools in 2025 (Ranked)
October 3, 2025

Manually typing every email, report, and note is a significant time drain. Speech-to-text software offers a powerful solution, converting your spoken words into accurate text instantly. This frees up your time, boosts productivity, and can even make writing more accessible for those with physical limitations. But with dozens of options available, each with unique strengths and weaknesses, choosing the right tool can be overwhelming.
This guide cuts through the noise. We've analyzed the leading platforms to help you find the best speech to text software for your specific needs. Whether you're a professional dictating medical notes, a content creator transcribing interviews, or a developer integrating voice commands, this list provides a clear, practical breakdown. From everyday dictation to specialized applications, speech-to-text technology offers immense value in various sectors, including leveraging AI for transcribing police bodycam footage in legal contexts.
We will evaluate each tool based on real-world use cases, accuracy, and pricing. You'll find direct links and screenshots for every option, alongside an honest look at their pros and cons. Our goal is to equip you with the insights needed to select a voice-to-text partner that fits seamlessly into your workflow.
1. VoiceType AI
Best For: Professionals seeking maximum speed and AI-powered accuracy.
VoiceType AI establishes itself as a top-tier solution for anyone looking to dramatically accelerate their writing workflow. It isn't just a simple dictation tool; it's an AI-powered co-writer that integrates directly into any application you use, from email clients to code editors. The platform promises to make you up to nine times faster than traditional typing, a claim supported by its impressive transcription speed of 360 words per minute.
What truly sets VoiceType AI apart is its intelligent feature set, which goes far beyond basic transcription. It leverages advanced AI to provide real-time auto-formatting, context-aware tone refinement, and correction of common mistakes like misspelled names. This makes it one of the best speech to text software options for producing polished, ready-to-use text without extensive manual editing.
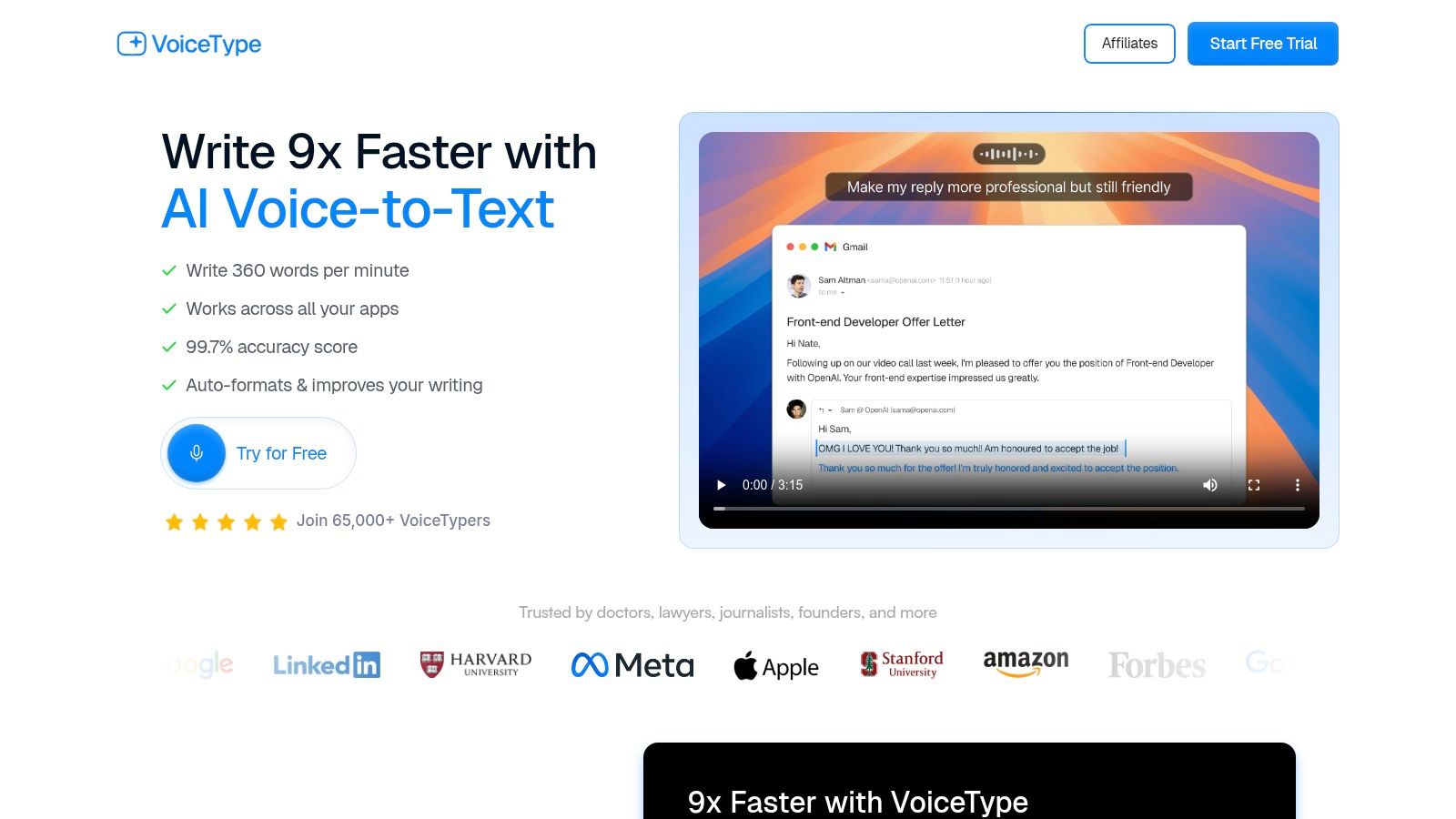
Key Features & Use Cases
This platform is engineered for high-stakes professional environments where clarity and efficiency are non-negotiable. Its commitment to data privacy, with all processing handled on private, encrypted servers, makes it a trusted choice for doctors, lawyers, and engineers.
Advanced AI Correction: Automatically fixes common dictation errors and adapts to your vocabulary, ensuring a high accuracy rate of 99.7%. This is ideal for medical professionals dictating complex patient notes or developers documenting intricate code.
Whisper Mode: Allows users to dictate discreetly in quiet or shared environments, such as open-plan offices or libraries, without disturbing others.
Global Accessibility: With support for over 35 languages, it's a versatile tool for international teams and multilingual professionals.
Seamless Integration: VoiceType works anywhere you can type on your laptop, eliminating the need to copy and paste from a separate window. This is perfect for drafting legal briefs in Microsoft Word or responding to customer queries in a CRM.
Pros & Cons
Pros | Cons |
|---|---|
Up to 9x faster writing with speeds of 360 wpm and 99.7% accuracy. | Subscription pricing details are general; users must visit the site for specific plans and costs. |
Advanced AI features like auto-formatting, tone adaptation, and error correction. | Extremely noisy environments might affect accuracy despite advanced noise handling. |
Supports over 35 languages and runs on private, encrypted servers, ensuring data privacy. | |
Discreet Whisper Mode allows comfortable use in shared or quiet environments. | |
Trusted by 650,000+ professionals across diverse industries, backed by strong social proof. |
Pricing: VoiceType AI offers subscription-based plans and includes a free trial to test its full capabilities. An ROI calculator on their website helps potential users quantify time and cost savings.
Website: https://voicetype.com
2. Nuance Dragon Professional
For professionals who require uncompromising accuracy and control for heavy daily dictation, Nuance Dragon Professional is the long-standing gold standard. Unlike cloud-based services, Dragon runs locally on your Windows machine, offering robust offline functionality and a high degree of customization for specialized vocabularies. This makes it a top-tier choice for legal, medical, and corporate environments where precision and data privacy are paramount.
Its core strength lies in its ability to learn your voice, accent, and specific terminology over time, achieving accuracy rates that often surpass cloud-based competitors for a single speaker. The software’s deep integration with Windows and Microsoft Office allows users to create documents, send emails, and navigate applications almost entirely by voice.

Key Features & Use Cases
Dragon excels where other tools falter: in high-stakes professional dictation. It's some of the best speech to text software available for hands-free productivity.
Custom Vocabularies & Macros: Ideal for professionals who use specific industry jargon. You can create custom commands to insert boilerplate text or perform multi-step tasks with a single voice command.
On-Device Processing: All voice recognition happens on your local machine, ensuring privacy and eliminating per-minute transcription fees.
Single-Speaker Transcription: Excellent for transcribing audio recordings of your own voice, such as dictated notes or drafts.
Best For: Professionals in specialized fields, individuals needing accessibility tools, and anyone who dictates for several hours a day. It is particularly powerful in healthcare; you can explore the use of Dragon in medical contexts to understand its specialized applications.
Pricing and Availability
Dragon Professional: A one-time purchase, typically around $699.
Availability: Windows 10/11 only. Note that Nuance’s direct web store has had intermittent pauses, so purchasing from a certified reseller is often the most reliable method.
Pros | Cons |
|---|---|
Exceptional accuracy for trained users | Windows-only platform |
Offline functionality avoids cloud fees | Not designed for multi-speaker meetings |
Deep customization for workflows | High upfront cost |
3. Amazon (marketplace category: Voice Recognition software)
While not a software tool itself, Amazon's marketplace is a critical resource for purchasing licenses, particularly for on-device software like Dragon Professional. Given that direct sales from developers can be inconsistent, Amazon provides a reliable, fast, and often competitively priced alternative for acquiring boxed or digital download versions. This makes it an essential hub for professionals who have decided on a specific local software solution.
The platform's strength lies in its vast seller network and user-centric features. Buyers can compare prices from various certified resellers, read user reviews to verify product versions, and leverage Prime shipping for quick delivery. For anyone needing to acquire some of the best speech to text software without navigating complex vendor websites, Amazon offers a streamlined and trusted purchasing experience.
Key Features & Use Cases
Amazon excels as a centralized and dependable marketplace for acquiring premium dictation software, especially when direct channels are unavailable.
Wide Selection & Seller Competition: Access multiple editions of software like Dragon from various sellers, leading to competitive pricing and frequent deals.
User Reviews and Ratings: Validate specific software versions and seller reliability by reading feedback from other professionals who have already made a purchase.
Fast & Reliable Delivery: Utilize Prime shipping for physical copies or get instant access with digital download codes, ensuring you can get started quickly.
Best For: Professionals and individuals who have chosen a specific on-premise software (like Dragon) and need a reliable, fast, and easy way to purchase it.
Pricing and Availability
Varies by Seller: Prices fluctuate based on the software version, seller, and current promotions. It is a marketplace, so costs are not fixed.
Availability: Primarily serves as a purchasing hub for Windows-based software. You can find licenses at Amazon's Voice Recognition Software category.
Pros | Cons |
|---|---|
Easy and reliable place to buy Dragon | Must carefully verify version and edition |
Competitive pricing due to multiple sellers | Some listings may feature outdated software |
Fast shipping and digital delivery options | Not a software service, but a retailer |
4. Otter.ai
For teams and individuals who need to capture, understand, and share conversations, Otter.ai has become the go-to platform for transcribing meetings. It excels at turning live or recorded audio from platforms like Zoom, Google Meet, and Microsoft Teams into searchable, shareable, and actionable notes. Its focus is less on pure dictation and more on collaborative intelligence.
Otter’s key differentiator is its AI-powered meeting assistant, which can automatically join your calendar events to record and transcribe them. During the meeting, it provides a real-time transcript where attendees can highlight key points, add comments, and assign action items, transforming a simple recording into a collaborative workspace. This makes it some of the best speech to text software for organizational productivity.
Key Features & Use Cases
Otter.ai is built to streamline meeting workflows and create a single source of truth for team conversations.
Automated Meeting Assistant: Integrates with your calendar to automatically join, record, and transcribe meetings, providing an AI-generated summary afterward.
Live Collaboration: Users can highlight text, add comments, and tag speakers in the live transcript, making it easy to capture decisions and action items.
Centralized Conversation Library: All transcripts are stored and fully searchable, creating an accessible knowledge base for your team.
Best For: Teams needing to document meetings, students recording lectures, and anyone who wants to create searchable records of multi-speaker conversations.
Pricing and Availability
Basic: Free plan with limited transcription minutes.
Pro: $16.99/month for individuals needing more minutes and features.
Business: $30/user/month, offering team features and higher usage limits.
Availability: Accessible via web and mobile apps for iOS and Android.
Pros | Cons |
|---|---|
Excellent for meetings and multi-speaker audio | Free and Pro plans have transcription minute limits |
Strong collaboration and summarization features | Highest security/compliance (HIPAA) is Enterprise-only |
Easy to use and integrates with major calendars | Accuracy can vary with heavy accents or poor audio |
5. Rev.com
For situations where absolute accuracy is non-negotiable, Rev.com offers a powerful hybrid model that combines industry-leading AI with a network of human transcriptionists. While many tools focus solely on automated solutions, Rev provides a crucial fallback for crystal-clear transcripts of complex audio, such as multi-speaker interviews, focus groups, or recordings with heavy accents and background noise.
This dual approach makes it a uniquely reliable service. Users can opt for the fast, affordable AI transcription for general use or escalate to human-powered services for final drafts, legal depositions, or broadcast-quality captions where precision is paramount. The platform’s simple, per-minute pricing structure and straightforward ordering process remove the guesswork from getting high-quality transcripts.
Key Features & Use Cases
Rev's strength lies in its guaranteed accuracy, making it some of the best speech to text software when an AI-only approach isn't enough.
Human Transcription: Its flagship service delivers 99% accuracy by using professional human transcriptionists, ideal for legal, academic, and media production.
AI Transcription & Captions: For quicker, lower-cost needs, its automated service provides a fast and reliable alternative for meeting notes or draft content.
Interactive Editor: All transcripts come with an interactive editor that syncs the audio with the text, making review and edits simple and efficient.
Best For: Podcasters, journalists, researchers, and legal professionals who need publish-ready, highly accurate transcripts and cannot risk errors from fully automated systems.
Pricing and Availability
Human Transcription: Starts at $1.50 per audio minute.
AI Transcription: Starts at $0.25 per audio minute.
Availability: Web-based platform, accessible from any device. Visit Rev.com/pricing for full details.
Pros | Cons |
|---|---|
Industry-leading 99% accuracy via humans | Human service costs can be high for bulk audio |
Simple, transparent per-minute pricing | Automated AI is less accurate than top competitors |
Fast turnaround times for both services | Not ideal for real-time dictation |
6. Descript
Descript flips the script on traditional transcription by treating audio and video as editable text. It’s an all-in-one platform built for creators, podcasters, and marketing teams who need to move seamlessly from raw recording to a polished, published product. Instead of complex timelines, you edit your media by simply deleting words or sentences in the generated transcript, making it incredibly intuitive for anyone comfortable with a word processor.
Its true innovation lies in this transcript-driven workflow. Correcting a mistranscribed word automatically corrects the audio, while features like one-click filler word removal ("um," "uh") and Studio Sound audio enhancement can save hours of tedious manual editing. This makes it some of the best speech to text software for content production.
Key Features & Use Cases
Descript excels in production workflows where the transcript is not just the output but the editing tool itself.
Text-Based Editing: Ideal for podcasters and video creators. Edit your audio/video by editing the transcript, a much faster process than using traditional timeline-based editors.
Automatic Filler Word Removal: Instantly find and delete all instances of "ums" and "ahs" to clean up audio recordings with a single click.
Screen Recording & Overdub: Perfect for tutorials, marketing videos, and corporate training. Record your screen and easily correct any spoken mistakes using an AI-generated clone of your voice.
Best For: Podcasters, YouTubers, marketers, and collaborative teams who need an integrated solution for recording, transcribing, and editing audio and video content.
Pricing and Availability
Free: Includes 1 hour of transcription per month.
Creator: $12/user/month (billed annually) for 10 hours/month.
Pro: $24/user/month (billed annually) for 30 hours/month.
Business: Custom pricing for teams needing collaboration controls.
Availability: Available on Mac and Windows. You can learn more at https://www.descript.com/pricing.
Pros | Cons |
|---|---|
Creator-friendly integrated workflow | Pricing complexity depends on usage |
Powerful text-based video/audio editing | Not ideal for simple, one-off transcription |
Excellent tools for audio cleanup | Plan changes require monitoring usage credits |
7. Sonix.ai
For content creators, researchers, and global teams who need fast, accurate transcriptions with extensive export and collaboration options, Sonix.ai stands out as a powerful automated service. It’s designed to process audio and video files quickly, turning them into editable, searchable text with speaker labeling and timestamps. The platform is entirely cloud-based, offering a streamlined workflow from upload to final export.
Its primary strength is its balance of speed, accuracy, and post-transcription tools. Sonix provides an interactive editor that synchronizes the text with the audio, allowing for easy review and correction. This focus on usability and flexible output formats makes it an excellent choice for journalists, podcasters, and video producers who need to create transcripts, captions, or subtitles efficiently.
Key Features & Use Cases
Sonix is some of the best speech to text software for teams that need to process and repurpose audio or video content without a steep learning curve.
Automated Transcription & Translation: Quickly transcribes from over 38 languages and offers an add-on service to translate the finished transcript into dozens more.
Collaborative Editor: The in-browser editor allows team members to view, edit, and comment on transcripts, streamlining the review process for projects.
Extensive Export Options: Exports transcripts into numerous formats, including Microsoft Word, TXT, PDF, and subtitle files like SRT and VTT.
Best For: Podcasters, video editors, journalists, researchers, and marketing teams needing to transcribe interviews, meetings, or media files for content creation and analysis.
Pricing and Availability
Standard (Pay-as-you-go): $10 per hour.
Premium Subscription: $5 per hour plus a $22 per user/month fee, offering more collaborative features.
Availability: Accessible via any modern web browser. Explore plans at Sonix.ai.
Pros | Cons |
|---|---|
Simple, predictable pricing | Translation and other add-ons cost extra |
Robust export formats (SRT, VTT, Word) | No human review service is offered |
Strong team collaboration features | Accuracy can vary with poor audio quality |
8. Deepgram
For developers and enterprises needing to build voice-enabled applications, Deepgram provides a high-performance, API-first speech-to-text platform. It's engineered for speed and scalability, offering real-time streaming and pre-recorded transcription models that are both fast and cost-effective. Unlike consumer-facing tools, Deepgram is a foundational layer for products that require voice data processing, from conversational AI to media transcription.
Its modern architecture is designed for developers, offering extensive documentation and powerful features like speaker diarization, PII redaction, and entity detection. With a focus on performance and low-latency streaming, Deepgram has become a go-to choice for companies building real-time voice agents, analytics platforms, and other demanding voice applications.
Key Features & Use Cases
Deepgram is some of the best speech to text software for developers who need to integrate transcription directly into their products and workflows.
Real-Time Streaming: Optimized for low latency, making it ideal for voice bots, live captioning, and conversational AI applications.
Advanced Audio Intelligence: Offers features like speaker diarization, topic detection, and PII redaction to enrich transcription data.
Developer-Focused: Provides robust SDKs, clear API documentation, and generous free credits for developers to start building.
Best For: Software developers, product teams, and enterprises building voice-enabled applications, contact center analytics solutions, or media processing pipelines. You can explore how it compares to other solutions in our review of the best AI transcription software.
Pricing and Availability
Pay-as-you-go: Highly competitive per-minute pricing that varies by model. Starts with a generous free credit tier.
Availability: Accessible globally via API. More information is available on the Deepgram pricing page.
Pros | Cons |
|---|---|
Highly competitive pricing | Purely an API, no consumer interface |
Fast real-time streaming | Requires development resources |
Excellent developer tools | Not suited for simple file uploads |
9. Google Cloud Speech-to-Text
For developers and enterprises needing to integrate high-quality, scalable voice recognition into their applications, Google Cloud Speech-to-Text provides a powerful and mature API. This service is a core component of the Google Cloud Platform, offering the same technology that powers products like Google Assistant. It excels at both real-time streaming for live applications and batch processing of large audio file archives.
Its main advantage is the flexibility and depth of its models, including specialized options for medical transcription and multi-channel audio from call centers. The API is robust, well-documented, and designed for high-volume use cases where reliability and integration with other cloud services are critical.

Key Features & Use Cases
Google’s API is some of the best speech to text software for building voice-enabled products and analyzing audio data at scale.
Standard & Medical Models: Choose from general-purpose models or a HIPAA-eligible model fine-tuned for medical terminology and doctor-patient conversations.
Speaker Diarization: Automatically identify and label different speakers in a single audio file, which is crucial for transcribing meetings or interviews.
Streaming & Batch Processing: Supports both live, real-time transcription for applications and efficient processing of large volumes of pre-recorded audio.
Best For: Developers building voice-controlled apps, businesses analyzing call center audio, and companies needing to transcribe large media archives.
Pricing and Availability
Pay-As-You-Go: Billed per minute of audio processed, with a generous free tier each month. Pricing varies by model (Standard, Medical, etc.) and offers discounts for high-volume usage.
Availability: Accessible globally via the Google Cloud Platform. Requires a Google Cloud account with billing set up. This comprehensive review of Google Cloud Speech-to-Text provides more detail on its capabilities.
Pros | Cons |
|---|---|
Highly scalable and reliable | Requires a Google Cloud account and billing setup |
Excellent integration with other Google services | Pricing can be complex to calculate |
Extensive language support | Primarily for developers, not a consumer-facing app |
10. Amazon Transcribe (AWS)
For developers and businesses building applications that require scalable, high-quality speech recognition, Amazon Transcribe is a core component of the AWS ecosystem. This cloud-based, fully managed service makes it easy to add speech-to-text capabilities to any application via an API. It's designed for high-volume, automated workflows rather than direct end-user dictation, excelling at processing large batches of audio files stored in Amazon S3 or transcribing real-time audio streams.
Its key differentiator is its deep integration with other AWS services, allowing for powerful, automated data pipelines. For instance, you can automatically transcribe customer service calls and then analyze the text for sentiment with Amazon Comprehend. This makes it some of the best speech to text software for companies already invested in the AWS platform seeking to unlock insights from audio data at scale.
Key Features & Use Cases
Amazon Transcribe is built for programmatic use, enabling everything from call center analytics to media content indexing.
Speaker Diarization & Channel Identification: Automatically identifies "who spoke when" and can process separate audio channels, making it ideal for transcribing multi-participant recordings like interviews or support calls.
PII Redaction: Can automatically detect and redact personally identifiable information (PII) from transcripts to help with compliance and privacy requirements.
Custom Vocabularies: Allows you to improve transcription accuracy for domain-specific terms, product names, or unique acronyms that are not in the standard dictionary.
Best For: Developers building voice-enabled applications, businesses needing to analyze call center recordings, and media companies looking to create searchable archives of audio/video content.
Pricing and Availability
Pay-As-You-Go: Billed per second of audio transcribed, with a free tier for new customers. Standard transcription rates are typically around $0.024 per minute. See the official AWS pricing page for details.
Availability: Accessible globally via the AWS cloud platform.
Pros | Cons |
|---|---|
Highly scalable and reliable | Not a user-facing application; requires technical expertise |
Deep integration with the AWS ecosystem | Billing can be complex with multiple AWS services involved |
Advanced features like PII redaction | Setup can be overwhelming for those new to AWS |
11. Microsoft Azure AI Speech (Speech to Text)
For organizations already embedded in the Microsoft ecosystem, Azure AI Speech provides a powerful, enterprise-grade transcription service that integrates seamlessly with other Azure services. It's a cloud-based solution designed for scalability, supporting both real-time streaming for applications like voice assistants and batch processing for transcribing large audio files. Its flexibility makes it a strong contender for developers building voice-enabled applications and businesses needing reliable, large-scale transcription.
The service's core advantage is its deep customization and deployment flexibility. Users can train custom models with domain-specific data to improve accuracy for technical jargon, unique names, or accented speech. Furthermore, its ability to be deployed in containers offers a hybrid approach, allowing businesses to run the transcription engine on-premises for enhanced data privacy and control.

Key Features & Use Cases
Azure AI Speech is some of the best speech to text software for developers and enterprises needing a scalable and customizable transcription engine.
Custom Models: Train the AI on your specific terminology, such as product names or industry-specific acronyms, to achieve higher accuracy than generic models.
Speaker Diarization: Automatically identifies and labels who is speaking in a conversation, making it ideal for transcribing meetings, interviews, or call center recordings.
Flexible Deployment: Run the service in the Azure cloud or deploy it on your own infrastructure using containers for compliance and data residency requirements.
Best For: Developers building voice-enabled products, large enterprises standardizing on Microsoft technologies, and organizations with strict data privacy or compliance needs.
Pricing and Availability
Free Tier: Includes a generous monthly quota of free audio hours.
Pay-as-you-go: Billed per audio hour, with pricing varying by feature and region. Commitment tiers are available for discounted rates.
Availability: Accessible globally via the Azure Speech Services portal.
Pros | Cons |
|---|---|
Excellent for Microsoft-centric organizations | Pricing tables can be complex to navigate |
Flexible hybrid deployment with containers | May require portal verification for exact costs |
Strong customization and scalability | Less intuitive for non-developers |
12. OpenAI Audio (Whisper API + Realtime/Audio models)
For developers and businesses seeking a powerful, scalable, and cost-effective transcription engine to build into their own applications, OpenAI's audio models are a dominant force. The platform is anchored by Whisper, a highly accurate model renowned for its performance on a diverse range of audio, accents, and background noise. It's less of a consumer-facing tool and more of a foundational technology for developers.
The introduction of real-time models like GPT-4o's audio capabilities has pushed the boundaries further, unifying speech-to-text, language processing, and text-to-speech into a single, low-latency stream. This enables the creation of highly responsive and natural-sounding conversational AI agents, moving beyond simple transcription to interactive voice experiences.
Key Features & Use Cases
OpenAI provides the building blocks for some of the best speech to text software integrations available today, from simple file processing to complex conversational AI.
Whisper API: Ideal for asynchronous transcription of audio/video files. It can handle various formats and includes robust language detection and translation capabilities.
Realtime Audio Models: Designed for interactive applications like voice assistants, real-time translation, and AI customer service agents where minimal latency is critical.
High Accuracy: The models are trained on a massive and diverse dataset, providing excellent accuracy across different languages, accents, and audio conditions without user-specific training.
Best For: Developers building voice-enabled applications, businesses needing bulk transcription for analytics, and creators integrating automated captions or subtitles into their platforms.
Pricing and Availability
Whisper API: Pay-as-you-go, priced per minute of audio processed (e.g., $0.006/minute).
Real-time/Audio-in: Priced on a token-based model, similar to their language models.
Availability: Accessible globally via the OpenAI API.
Pros | Cons |
|---|---|
Exceptional accuracy on diverse audio | Requires technical expertise (API-based) |
Very low cost-per-minute for Whisper | Fewer native tools for diarization |
Realtime models enable conversational AI | Whisper API has a 25MB file size limit |
Top 12 Speech-to-Text Software Comparison
Product | Core Features & Accuracy | User Experience & Quality ★ | Value Proposition & Pricing 💰 | Target Audience 👥 | Unique Selling Points ✨ |
|---|---|---|---|---|---|
🏆 VoiceType AI | 99.7% accuracy, 360 wpm, 35+ languages, encrypted | High accuracy, auto-formatting, tone adaption | Affordable subscriptions, ROI calculator | Professionals, marketers, doctors, journalists, execs | Whisper Mode, context-tailored text, multi-app use |
Nuance Dragon Professional | On-device Windows dictation, custom vocabularies | Very high accuracy for trained users | One-time purchase, no cloud fees | Windows professionals, accessibility users | Offline use, macros, Dragon Anywhere integration |
Amazon Voice Recognition | Marketplace for various voice software | Ratings & reviews for validation | Competitive pricing, deals | Buyers seeking Dragon and other software | Easy purchase, Prime shipping |
Otter.ai | Live transcription, calendar integration, multi-lang | Collaborative features, speaker tags | Free tier, Business plans | Teams transcribing meetings | AI Meeting Agent, automated summaries |
Rev.com | Human+AI transcription hybrid | 99% human accuracy, simple UI | Per-minute pricing, subscriptions | Projects needing accuracy & quick turnaround | Reliable human transcription, interactive editor |
Descript | Text-based audio/video editing | Creator-friendly, filler removal | Usage-based, complex pricing | Podcasters, creators, teams | Studio Sound, stock media, collaboration |
Sonix.ai | Pay-as-you-go/subscription, timestamps, translation | Predictable pricing, strong exports | Transparent plans | Global teams, batch transcription | API, custom dictionary, multiple export formats |
Deepgram | Real-time & batch transcription, developer API | Competitive pricing, strong docs | Pay-as-you-go | Developers, enterprises | PII redaction, Voice Agent API, free developer credits |
Google Cloud Speech-to-Text | Medical & standard models, speaker diarization | Mature platform, integrated with Google Cloud | Volume discounts, complex pricing | Enterprises, large volume users | Medical models, flexible APIs |
Amazon Transcribe (AWS) | Streaming & batch, vocab customization, HIPAA-eligible | Scalable, pay-as-you-go pricing | Usage-based pricing | AWS customers, enterprises | Deep AWS integration, contact center analytics |
Microsoft Azure AI Speech | Real-time & batch, custom models, containers | Flexible deployment, free quota | Complex pricing, regional variance | Microsoft/Azure based orgs | Pronunciation assessment, hybrid deployment |
OpenAI Audio (Whisper API) | Whisper API for transcription, realtime GPT-4o models | Low-cost Whisper pricing | Token-based pricing for realtime | Developers, low-latency voice app creators | Unified STT+LLM+TTS, very low per-minute cost |
Making Your Final Choice: Which Speech to Text Tool is Right for You?
Navigating the crowded market for the best speech to text software can feel overwhelming, but the right choice ultimately comes down to your specific needs and workflow. We've explored everything from polished, user-friendly applications designed for content creators and professionals to powerful, developer-focused APIs that offer unparalleled customization and scale. The key takeaway is that there is no single "best" solution for everyone; the ideal tool is the one that seamlessly integrates into your daily tasks and delivers the accuracy and features you require most.
Whether you're a journalist using Otter.ai for interview transcriptions, a developer leveraging Deepgram for real-time applications, or a medical professional relying on Nuance Dragon for clinical documentation, the perfect fit exists. Your decision hinges on a clear understanding of your primary use case.
How to Select the Right Tool for Your Needs
To make your final decision, move beyond feature lists and focus on practical application. Your evaluation should be guided by a few core questions that directly impact usability and performance in your specific environment.
What is your primary use case? Are you transcribing pre-recorded meetings (like with Rev.com or Sonix.ai), dictating content directly into documents (VoiceType AI, Dragon), or building a custom application that needs a speech recognition engine (AWS, Google Cloud, OpenAI)? Your core task dictates the type of software you need.
What level of accuracy is non-negotiable? For legal and medical fields, near-perfect accuracy with specialized vocabulary support is essential. For internal note-taking or drafting content, a slightly lower accuracy rate might be acceptable if the software offers superior speed and editing tools.
How important is real-time transcription? If you need live captions for webinars, virtual meetings, or customer support calls, prioritize tools that excel in real-time performance, such as Descript or dedicated APIs like Deepgram.
What is your technical comfort level? If you're not a developer, stick to out-of-the-box solutions with intuitive user interfaces. For those building custom software, evaluating APIs is critical. For a deeper dive into that specific area, reviewing detailed comparisons and criteria for finding the best Speech to Text API can provide the clarity needed to choose the right engine for your project.
What is your budget? Your budget will guide you toward a per-minute API pricing model, a flat-rate monthly subscription, or a one-time software purchase. Be sure to calculate the total cost based on your anticipated usage.
Your Next Steps
The journey to finding the best speech to text software for your needs ends with hands-on testing. Nearly every tool on this list offers a free trial or a free tier. Take advantage of it. Upload a sample audio file that represents your typical use case, paying close attention to any industry-specific jargon, accents, or background noise. This practical test will reveal more about a tool’s performance than any marketing copy ever could.
By aligning your specific requirements with the strengths of these powerful tools, you can unlock a new level of productivity, accessibility, and efficiency. The right software will feel less like a tool and more like an indispensable extension of your workflow, freeing you to focus on what matters most.
Ready to experience a dictation tool built for speed, accuracy, and seamless integration into your daily workflow? VoiceType AI is designed for professionals, writers, and students who need to capture their thoughts effortlessly. Try VoiceType AI today to see how fast, intuitive, and powerful voice-to-text can be.
Manually typing every email, report, and note is a significant time drain. Speech-to-text software offers a powerful solution, converting your spoken words into accurate text instantly. This frees up your time, boosts productivity, and can even make writing more accessible for those with physical limitations. But with dozens of options available, each with unique strengths and weaknesses, choosing the right tool can be overwhelming.
This guide cuts through the noise. We've analyzed the leading platforms to help you find the best speech to text software for your specific needs. Whether you're a professional dictating medical notes, a content creator transcribing interviews, or a developer integrating voice commands, this list provides a clear, practical breakdown. From everyday dictation to specialized applications, speech-to-text technology offers immense value in various sectors, including leveraging AI for transcribing police bodycam footage in legal contexts.
We will evaluate each tool based on real-world use cases, accuracy, and pricing. You'll find direct links and screenshots for every option, alongside an honest look at their pros and cons. Our goal is to equip you with the insights needed to select a voice-to-text partner that fits seamlessly into your workflow.
1. VoiceType AI
Best For: Professionals seeking maximum speed and AI-powered accuracy.
VoiceType AI establishes itself as a top-tier solution for anyone looking to dramatically accelerate their writing workflow. It isn't just a simple dictation tool; it's an AI-powered co-writer that integrates directly into any application you use, from email clients to code editors. The platform promises to make you up to nine times faster than traditional typing, a claim supported by its impressive transcription speed of 360 words per minute.
What truly sets VoiceType AI apart is its intelligent feature set, which goes far beyond basic transcription. It leverages advanced AI to provide real-time auto-formatting, context-aware tone refinement, and correction of common mistakes like misspelled names. This makes it one of the best speech to text software options for producing polished, ready-to-use text without extensive manual editing.
Key Features & Use Cases
This platform is engineered for high-stakes professional environments where clarity and efficiency are non-negotiable. Its commitment to data privacy, with all processing handled on private, encrypted servers, makes it a trusted choice for doctors, lawyers, and engineers.
Advanced AI Correction: Automatically fixes common dictation errors and adapts to your vocabulary, ensuring a high accuracy rate of 99.7%. This is ideal for medical professionals dictating complex patient notes or developers documenting intricate code.
Whisper Mode: Allows users to dictate discreetly in quiet or shared environments, such as open-plan offices or libraries, without disturbing others.
Global Accessibility: With support for over 35 languages, it's a versatile tool for international teams and multilingual professionals.
Seamless Integration: VoiceType works anywhere you can type on your laptop, eliminating the need to copy and paste from a separate window. This is perfect for drafting legal briefs in Microsoft Word or responding to customer queries in a CRM.
Pros & Cons
Pros | Cons |
|---|---|
Up to 9x faster writing with speeds of 360 wpm and 99.7% accuracy. | Subscription pricing details are general; users must visit the site for specific plans and costs. |
Advanced AI features like auto-formatting, tone adaptation, and error correction. | Extremely noisy environments might affect accuracy despite advanced noise handling. |
Supports over 35 languages and runs on private, encrypted servers, ensuring data privacy. | |
Discreet Whisper Mode allows comfortable use in shared or quiet environments. | |
Trusted by 650,000+ professionals across diverse industries, backed by strong social proof. |
Pricing: VoiceType AI offers subscription-based plans and includes a free trial to test its full capabilities. An ROI calculator on their website helps potential users quantify time and cost savings.
Website: https://voicetype.com
2. Nuance Dragon Professional
For professionals who require uncompromising accuracy and control for heavy daily dictation, Nuance Dragon Professional is the long-standing gold standard. Unlike cloud-based services, Dragon runs locally on your Windows machine, offering robust offline functionality and a high degree of customization for specialized vocabularies. This makes it a top-tier choice for legal, medical, and corporate environments where precision and data privacy are paramount.
Its core strength lies in its ability to learn your voice, accent, and specific terminology over time, achieving accuracy rates that often surpass cloud-based competitors for a single speaker. The software’s deep integration with Windows and Microsoft Office allows users to create documents, send emails, and navigate applications almost entirely by voice.
Key Features & Use Cases
Dragon excels where other tools falter: in high-stakes professional dictation. It's some of the best speech to text software available for hands-free productivity.
Custom Vocabularies & Macros: Ideal for professionals who use specific industry jargon. You can create custom commands to insert boilerplate text or perform multi-step tasks with a single voice command.
On-Device Processing: All voice recognition happens on your local machine, ensuring privacy and eliminating per-minute transcription fees.
Single-Speaker Transcription: Excellent for transcribing audio recordings of your own voice, such as dictated notes or drafts.
Best For: Professionals in specialized fields, individuals needing accessibility tools, and anyone who dictates for several hours a day. It is particularly powerful in healthcare; you can explore the use of Dragon in medical contexts to understand its specialized applications.
Pricing and Availability
Dragon Professional: A one-time purchase, typically around $699.
Availability: Windows 10/11 only. Note that Nuance’s direct web store has had intermittent pauses, so purchasing from a certified reseller is often the most reliable method.
Pros | Cons |
|---|---|
Exceptional accuracy for trained users | Windows-only platform |
Offline functionality avoids cloud fees | Not designed for multi-speaker meetings |
Deep customization for workflows | High upfront cost |
3. Amazon (marketplace category: Voice Recognition software)
While not a software tool itself, Amazon's marketplace is a critical resource for purchasing licenses, particularly for on-device software like Dragon Professional. Given that direct sales from developers can be inconsistent, Amazon provides a reliable, fast, and often competitively priced alternative for acquiring boxed or digital download versions. This makes it an essential hub for professionals who have decided on a specific local software solution.
The platform's strength lies in its vast seller network and user-centric features. Buyers can compare prices from various certified resellers, read user reviews to verify product versions, and leverage Prime shipping for quick delivery. For anyone needing to acquire some of the best speech to text software without navigating complex vendor websites, Amazon offers a streamlined and trusted purchasing experience.
Key Features & Use Cases
Amazon excels as a centralized and dependable marketplace for acquiring premium dictation software, especially when direct channels are unavailable.
Wide Selection & Seller Competition: Access multiple editions of software like Dragon from various sellers, leading to competitive pricing and frequent deals.
User Reviews and Ratings: Validate specific software versions and seller reliability by reading feedback from other professionals who have already made a purchase.
Fast & Reliable Delivery: Utilize Prime shipping for physical copies or get instant access with digital download codes, ensuring you can get started quickly.
Best For: Professionals and individuals who have chosen a specific on-premise software (like Dragon) and need a reliable, fast, and easy way to purchase it.
Pricing and Availability
Varies by Seller: Prices fluctuate based on the software version, seller, and current promotions. It is a marketplace, so costs are not fixed.
Availability: Primarily serves as a purchasing hub for Windows-based software. You can find licenses at Amazon's Voice Recognition Software category.
Pros | Cons |
|---|---|
Easy and reliable place to buy Dragon | Must carefully verify version and edition |
Competitive pricing due to multiple sellers | Some listings may feature outdated software |
Fast shipping and digital delivery options | Not a software service, but a retailer |
4. Otter.ai
For teams and individuals who need to capture, understand, and share conversations, Otter.ai has become the go-to platform for transcribing meetings. It excels at turning live or recorded audio from platforms like Zoom, Google Meet, and Microsoft Teams into searchable, shareable, and actionable notes. Its focus is less on pure dictation and more on collaborative intelligence.
Otter’s key differentiator is its AI-powered meeting assistant, which can automatically join your calendar events to record and transcribe them. During the meeting, it provides a real-time transcript where attendees can highlight key points, add comments, and assign action items, transforming a simple recording into a collaborative workspace. This makes it some of the best speech to text software for organizational productivity.
Key Features & Use Cases
Otter.ai is built to streamline meeting workflows and create a single source of truth for team conversations.
Automated Meeting Assistant: Integrates with your calendar to automatically join, record, and transcribe meetings, providing an AI-generated summary afterward.
Live Collaboration: Users can highlight text, add comments, and tag speakers in the live transcript, making it easy to capture decisions and action items.
Centralized Conversation Library: All transcripts are stored and fully searchable, creating an accessible knowledge base for your team.
Best For: Teams needing to document meetings, students recording lectures, and anyone who wants to create searchable records of multi-speaker conversations.
Pricing and Availability
Basic: Free plan with limited transcription minutes.
Pro: $16.99/month for individuals needing more minutes and features.
Business: $30/user/month, offering team features and higher usage limits.
Availability: Accessible via web and mobile apps for iOS and Android.
Pros | Cons |
|---|---|
Excellent for meetings and multi-speaker audio | Free and Pro plans have transcription minute limits |
Strong collaboration and summarization features | Highest security/compliance (HIPAA) is Enterprise-only |
Easy to use and integrates with major calendars | Accuracy can vary with heavy accents or poor audio |
5. Rev.com
For situations where absolute accuracy is non-negotiable, Rev.com offers a powerful hybrid model that combines industry-leading AI with a network of human transcriptionists. While many tools focus solely on automated solutions, Rev provides a crucial fallback for crystal-clear transcripts of complex audio, such as multi-speaker interviews, focus groups, or recordings with heavy accents and background noise.
This dual approach makes it a uniquely reliable service. Users can opt for the fast, affordable AI transcription for general use or escalate to human-powered services for final drafts, legal depositions, or broadcast-quality captions where precision is paramount. The platform’s simple, per-minute pricing structure and straightforward ordering process remove the guesswork from getting high-quality transcripts.
Key Features & Use Cases
Rev's strength lies in its guaranteed accuracy, making it some of the best speech to text software when an AI-only approach isn't enough.
Human Transcription: Its flagship service delivers 99% accuracy by using professional human transcriptionists, ideal for legal, academic, and media production.
AI Transcription & Captions: For quicker, lower-cost needs, its automated service provides a fast and reliable alternative for meeting notes or draft content.
Interactive Editor: All transcripts come with an interactive editor that syncs the audio with the text, making review and edits simple and efficient.
Best For: Podcasters, journalists, researchers, and legal professionals who need publish-ready, highly accurate transcripts and cannot risk errors from fully automated systems.
Pricing and Availability
Human Transcription: Starts at $1.50 per audio minute.
AI Transcription: Starts at $0.25 per audio minute.
Availability: Web-based platform, accessible from any device. Visit Rev.com/pricing for full details.
Pros | Cons |
|---|---|
Industry-leading 99% accuracy via humans | Human service costs can be high for bulk audio |
Simple, transparent per-minute pricing | Automated AI is less accurate than top competitors |
Fast turnaround times for both services | Not ideal for real-time dictation |
6. Descript
Descript flips the script on traditional transcription by treating audio and video as editable text. It’s an all-in-one platform built for creators, podcasters, and marketing teams who need to move seamlessly from raw recording to a polished, published product. Instead of complex timelines, you edit your media by simply deleting words or sentences in the generated transcript, making it incredibly intuitive for anyone comfortable with a word processor.
Its true innovation lies in this transcript-driven workflow. Correcting a mistranscribed word automatically corrects the audio, while features like one-click filler word removal ("um," "uh") and Studio Sound audio enhancement can save hours of tedious manual editing. This makes it some of the best speech to text software for content production.
Key Features & Use Cases
Descript excels in production workflows where the transcript is not just the output but the editing tool itself.
Text-Based Editing: Ideal for podcasters and video creators. Edit your audio/video by editing the transcript, a much faster process than using traditional timeline-based editors.
Automatic Filler Word Removal: Instantly find and delete all instances of "ums" and "ahs" to clean up audio recordings with a single click.
Screen Recording & Overdub: Perfect for tutorials, marketing videos, and corporate training. Record your screen and easily correct any spoken mistakes using an AI-generated clone of your voice.
Best For: Podcasters, YouTubers, marketers, and collaborative teams who need an integrated solution for recording, transcribing, and editing audio and video content.
Pricing and Availability
Free: Includes 1 hour of transcription per month.
Creator: $12/user/month (billed annually) for 10 hours/month.
Pro: $24/user/month (billed annually) for 30 hours/month.
Business: Custom pricing for teams needing collaboration controls.
Availability: Available on Mac and Windows. You can learn more at https://www.descript.com/pricing.
Pros | Cons |
|---|---|
Creator-friendly integrated workflow | Pricing complexity depends on usage |
Powerful text-based video/audio editing | Not ideal for simple, one-off transcription |
Excellent tools for audio cleanup | Plan changes require monitoring usage credits |
7. Sonix.ai
For content creators, researchers, and global teams who need fast, accurate transcriptions with extensive export and collaboration options, Sonix.ai stands out as a powerful automated service. It’s designed to process audio and video files quickly, turning them into editable, searchable text with speaker labeling and timestamps. The platform is entirely cloud-based, offering a streamlined workflow from upload to final export.
Its primary strength is its balance of speed, accuracy, and post-transcription tools. Sonix provides an interactive editor that synchronizes the text with the audio, allowing for easy review and correction. This focus on usability and flexible output formats makes it an excellent choice for journalists, podcasters, and video producers who need to create transcripts, captions, or subtitles efficiently.
Key Features & Use Cases
Sonix is some of the best speech to text software for teams that need to process and repurpose audio or video content without a steep learning curve.
Automated Transcription & Translation: Quickly transcribes from over 38 languages and offers an add-on service to translate the finished transcript into dozens more.
Collaborative Editor: The in-browser editor allows team members to view, edit, and comment on transcripts, streamlining the review process for projects.
Extensive Export Options: Exports transcripts into numerous formats, including Microsoft Word, TXT, PDF, and subtitle files like SRT and VTT.
Best For: Podcasters, video editors, journalists, researchers, and marketing teams needing to transcribe interviews, meetings, or media files for content creation and analysis.
Pricing and Availability
Standard (Pay-as-you-go): $10 per hour.
Premium Subscription: $5 per hour plus a $22 per user/month fee, offering more collaborative features.
Availability: Accessible via any modern web browser. Explore plans at Sonix.ai.
Pros | Cons |
|---|---|
Simple, predictable pricing | Translation and other add-ons cost extra |
Robust export formats (SRT, VTT, Word) | No human review service is offered |
Strong team collaboration features | Accuracy can vary with poor audio quality |
8. Deepgram
For developers and enterprises needing to build voice-enabled applications, Deepgram provides a high-performance, API-first speech-to-text platform. It's engineered for speed and scalability, offering real-time streaming and pre-recorded transcription models that are both fast and cost-effective. Unlike consumer-facing tools, Deepgram is a foundational layer for products that require voice data processing, from conversational AI to media transcription.
Its modern architecture is designed for developers, offering extensive documentation and powerful features like speaker diarization, PII redaction, and entity detection. With a focus on performance and low-latency streaming, Deepgram has become a go-to choice for companies building real-time voice agents, analytics platforms, and other demanding voice applications.
Key Features & Use Cases
Deepgram is some of the best speech to text software for developers who need to integrate transcription directly into their products and workflows.
Real-Time Streaming: Optimized for low latency, making it ideal for voice bots, live captioning, and conversational AI applications.
Advanced Audio Intelligence: Offers features like speaker diarization, topic detection, and PII redaction to enrich transcription data.
Developer-Focused: Provides robust SDKs, clear API documentation, and generous free credits for developers to start building.
Best For: Software developers, product teams, and enterprises building voice-enabled applications, contact center analytics solutions, or media processing pipelines. You can explore how it compares to other solutions in our review of the best AI transcription software.
Pricing and Availability
Pay-as-you-go: Highly competitive per-minute pricing that varies by model. Starts with a generous free credit tier.
Availability: Accessible globally via API. More information is available on the Deepgram pricing page.
Pros | Cons |
|---|---|
Highly competitive pricing | Purely an API, no consumer interface |
Fast real-time streaming | Requires development resources |
Excellent developer tools | Not suited for simple file uploads |
9. Google Cloud Speech-to-Text
For developers and enterprises needing to integrate high-quality, scalable voice recognition into their applications, Google Cloud Speech-to-Text provides a powerful and mature API. This service is a core component of the Google Cloud Platform, offering the same technology that powers products like Google Assistant. It excels at both real-time streaming for live applications and batch processing of large audio file archives.
Its main advantage is the flexibility and depth of its models, including specialized options for medical transcription and multi-channel audio from call centers. The API is robust, well-documented, and designed for high-volume use cases where reliability and integration with other cloud services are critical.
Key Features & Use Cases
Google’s API is some of the best speech to text software for building voice-enabled products and analyzing audio data at scale.
Standard & Medical Models: Choose from general-purpose models or a HIPAA-eligible model fine-tuned for medical terminology and doctor-patient conversations.
Speaker Diarization: Automatically identify and label different speakers in a single audio file, which is crucial for transcribing meetings or interviews.
Streaming & Batch Processing: Supports both live, real-time transcription for applications and efficient processing of large volumes of pre-recorded audio.
Best For: Developers building voice-controlled apps, businesses analyzing call center audio, and companies needing to transcribe large media archives.
Pricing and Availability
Pay-As-You-Go: Billed per minute of audio processed, with a generous free tier each month. Pricing varies by model (Standard, Medical, etc.) and offers discounts for high-volume usage.
Availability: Accessible globally via the Google Cloud Platform. Requires a Google Cloud account with billing set up. This comprehensive review of Google Cloud Speech-to-Text provides more detail on its capabilities.
Pros | Cons |
|---|---|
Highly scalable and reliable | Requires a Google Cloud account and billing setup |
Excellent integration with other Google services | Pricing can be complex to calculate |
Extensive language support | Primarily for developers, not a consumer-facing app |
10. Amazon Transcribe (AWS)
For developers and businesses building applications that require scalable, high-quality speech recognition, Amazon Transcribe is a core component of the AWS ecosystem. This cloud-based, fully managed service makes it easy to add speech-to-text capabilities to any application via an API. It's designed for high-volume, automated workflows rather than direct end-user dictation, excelling at processing large batches of audio files stored in Amazon S3 or transcribing real-time audio streams.
Its key differentiator is its deep integration with other AWS services, allowing for powerful, automated data pipelines. For instance, you can automatically transcribe customer service calls and then analyze the text for sentiment with Amazon Comprehend. This makes it some of the best speech to text software for companies already invested in the AWS platform seeking to unlock insights from audio data at scale.
Key Features & Use Cases
Amazon Transcribe is built for programmatic use, enabling everything from call center analytics to media content indexing.
Speaker Diarization & Channel Identification: Automatically identifies "who spoke when" and can process separate audio channels, making it ideal for transcribing multi-participant recordings like interviews or support calls.
PII Redaction: Can automatically detect and redact personally identifiable information (PII) from transcripts to help with compliance and privacy requirements.
Custom Vocabularies: Allows you to improve transcription accuracy for domain-specific terms, product names, or unique acronyms that are not in the standard dictionary.
Best For: Developers building voice-enabled applications, businesses needing to analyze call center recordings, and media companies looking to create searchable archives of audio/video content.
Pricing and Availability
Pay-As-You-Go: Billed per second of audio transcribed, with a free tier for new customers. Standard transcription rates are typically around $0.024 per minute. See the official AWS pricing page for details.
Availability: Accessible globally via the AWS cloud platform.
Pros | Cons |
|---|---|
Highly scalable and reliable | Not a user-facing application; requires technical expertise |
Deep integration with the AWS ecosystem | Billing can be complex with multiple AWS services involved |
Advanced features like PII redaction | Setup can be overwhelming for those new to AWS |
11. Microsoft Azure AI Speech (Speech to Text)
For organizations already embedded in the Microsoft ecosystem, Azure AI Speech provides a powerful, enterprise-grade transcription service that integrates seamlessly with other Azure services. It's a cloud-based solution designed for scalability, supporting both real-time streaming for applications like voice assistants and batch processing for transcribing large audio files. Its flexibility makes it a strong contender for developers building voice-enabled applications and businesses needing reliable, large-scale transcription.
The service's core advantage is its deep customization and deployment flexibility. Users can train custom models with domain-specific data to improve accuracy for technical jargon, unique names, or accented speech. Furthermore, its ability to be deployed in containers offers a hybrid approach, allowing businesses to run the transcription engine on-premises for enhanced data privacy and control.
Key Features & Use Cases
Azure AI Speech is some of the best speech to text software for developers and enterprises needing a scalable and customizable transcription engine.
Custom Models: Train the AI on your specific terminology, such as product names or industry-specific acronyms, to achieve higher accuracy than generic models.
Speaker Diarization: Automatically identifies and labels who is speaking in a conversation, making it ideal for transcribing meetings, interviews, or call center recordings.
Flexible Deployment: Run the service in the Azure cloud or deploy it on your own infrastructure using containers for compliance and data residency requirements.
Best For: Developers building voice-enabled products, large enterprises standardizing on Microsoft technologies, and organizations with strict data privacy or compliance needs.
Pricing and Availability
Free Tier: Includes a generous monthly quota of free audio hours.
Pay-as-you-go: Billed per audio hour, with pricing varying by feature and region. Commitment tiers are available for discounted rates.
Availability: Accessible globally via the Azure Speech Services portal.
Pros | Cons |
|---|---|
Excellent for Microsoft-centric organizations | Pricing tables can be complex to navigate |
Flexible hybrid deployment with containers | May require portal verification for exact costs |
Strong customization and scalability | Less intuitive for non-developers |
12. OpenAI Audio (Whisper API + Realtime/Audio models)
For developers and businesses seeking a powerful, scalable, and cost-effective transcription engine to build into their own applications, OpenAI's audio models are a dominant force. The platform is anchored by Whisper, a highly accurate model renowned for its performance on a diverse range of audio, accents, and background noise. It's less of a consumer-facing tool and more of a foundational technology for developers.
The introduction of real-time models like GPT-4o's audio capabilities has pushed the boundaries further, unifying speech-to-text, language processing, and text-to-speech into a single, low-latency stream. This enables the creation of highly responsive and natural-sounding conversational AI agents, moving beyond simple transcription to interactive voice experiences.
Key Features & Use Cases
OpenAI provides the building blocks for some of the best speech to text software integrations available today, from simple file processing to complex conversational AI.
Whisper API: Ideal for asynchronous transcription of audio/video files. It can handle various formats and includes robust language detection and translation capabilities.
Realtime Audio Models: Designed for interactive applications like voice assistants, real-time translation, and AI customer service agents where minimal latency is critical.
High Accuracy: The models are trained on a massive and diverse dataset, providing excellent accuracy across different languages, accents, and audio conditions without user-specific training.
Best For: Developers building voice-enabled applications, businesses needing bulk transcription for analytics, and creators integrating automated captions or subtitles into their platforms.
Pricing and Availability
Whisper API: Pay-as-you-go, priced per minute of audio processed (e.g., $0.006/minute).
Real-time/Audio-in: Priced on a token-based model, similar to their language models.
Availability: Accessible globally via the OpenAI API.
Pros | Cons |
|---|---|
Exceptional accuracy on diverse audio | Requires technical expertise (API-based) |
Very low cost-per-minute for Whisper | Fewer native tools for diarization |
Realtime models enable conversational AI | Whisper API has a 25MB file size limit |
Top 12 Speech-to-Text Software Comparison
Product | Core Features & Accuracy | User Experience & Quality ★ | Value Proposition & Pricing 💰 | Target Audience 👥 | Unique Selling Points ✨ |
|---|---|---|---|---|---|
🏆 VoiceType AI | 99.7% accuracy, 360 wpm, 35+ languages, encrypted | High accuracy, auto-formatting, tone adaption | Affordable subscriptions, ROI calculator | Professionals, marketers, doctors, journalists, execs | Whisper Mode, context-tailored text, multi-app use |
Nuance Dragon Professional | On-device Windows dictation, custom vocabularies | Very high accuracy for trained users | One-time purchase, no cloud fees | Windows professionals, accessibility users | Offline use, macros, Dragon Anywhere integration |
Amazon Voice Recognition | Marketplace for various voice software | Ratings & reviews for validation | Competitive pricing, deals | Buyers seeking Dragon and other software | Easy purchase, Prime shipping |
Otter.ai | Live transcription, calendar integration, multi-lang | Collaborative features, speaker tags | Free tier, Business plans | Teams transcribing meetings | AI Meeting Agent, automated summaries |
Rev.com | Human+AI transcription hybrid | 99% human accuracy, simple UI | Per-minute pricing, subscriptions | Projects needing accuracy & quick turnaround | Reliable human transcription, interactive editor |
Descript | Text-based audio/video editing | Creator-friendly, filler removal | Usage-based, complex pricing | Podcasters, creators, teams | Studio Sound, stock media, collaboration |
Sonix.ai | Pay-as-you-go/subscription, timestamps, translation | Predictable pricing, strong exports | Transparent plans | Global teams, batch transcription | API, custom dictionary, multiple export formats |
Deepgram | Real-time & batch transcription, developer API | Competitive pricing, strong docs | Pay-as-you-go | Developers, enterprises | PII redaction, Voice Agent API, free developer credits |
Google Cloud Speech-to-Text | Medical & standard models, speaker diarization | Mature platform, integrated with Google Cloud | Volume discounts, complex pricing | Enterprises, large volume users | Medical models, flexible APIs |
Amazon Transcribe (AWS) | Streaming & batch, vocab customization, HIPAA-eligible | Scalable, pay-as-you-go pricing | Usage-based pricing | AWS customers, enterprises | Deep AWS integration, contact center analytics |
Microsoft Azure AI Speech | Real-time & batch, custom models, containers | Flexible deployment, free quota | Complex pricing, regional variance | Microsoft/Azure based orgs | Pronunciation assessment, hybrid deployment |
OpenAI Audio (Whisper API) | Whisper API for transcription, realtime GPT-4o models | Low-cost Whisper pricing | Token-based pricing for realtime | Developers, low-latency voice app creators | Unified STT+LLM+TTS, very low per-minute cost |
Making Your Final Choice: Which Speech to Text Tool is Right for You?
Navigating the crowded market for the best speech to text software can feel overwhelming, but the right choice ultimately comes down to your specific needs and workflow. We've explored everything from polished, user-friendly applications designed for content creators and professionals to powerful, developer-focused APIs that offer unparalleled customization and scale. The key takeaway is that there is no single "best" solution for everyone; the ideal tool is the one that seamlessly integrates into your daily tasks and delivers the accuracy and features you require most.
Whether you're a journalist using Otter.ai for interview transcriptions, a developer leveraging Deepgram for real-time applications, or a medical professional relying on Nuance Dragon for clinical documentation, the perfect fit exists. Your decision hinges on a clear understanding of your primary use case.
How to Select the Right Tool for Your Needs
To make your final decision, move beyond feature lists and focus on practical application. Your evaluation should be guided by a few core questions that directly impact usability and performance in your specific environment.
What is your primary use case? Are you transcribing pre-recorded meetings (like with Rev.com or Sonix.ai), dictating content directly into documents (VoiceType AI, Dragon), or building a custom application that needs a speech recognition engine (AWS, Google Cloud, OpenAI)? Your core task dictates the type of software you need.
What level of accuracy is non-negotiable? For legal and medical fields, near-perfect accuracy with specialized vocabulary support is essential. For internal note-taking or drafting content, a slightly lower accuracy rate might be acceptable if the software offers superior speed and editing tools.
How important is real-time transcription? If you need live captions for webinars, virtual meetings, or customer support calls, prioritize tools that excel in real-time performance, such as Descript or dedicated APIs like Deepgram.
What is your technical comfort level? If you're not a developer, stick to out-of-the-box solutions with intuitive user interfaces. For those building custom software, evaluating APIs is critical. For a deeper dive into that specific area, reviewing detailed comparisons and criteria for finding the best Speech to Text API can provide the clarity needed to choose the right engine for your project.
What is your budget? Your budget will guide you toward a per-minute API pricing model, a flat-rate monthly subscription, or a one-time software purchase. Be sure to calculate the total cost based on your anticipated usage.
Your Next Steps
The journey to finding the best speech to text software for your needs ends with hands-on testing. Nearly every tool on this list offers a free trial or a free tier. Take advantage of it. Upload a sample audio file that represents your typical use case, paying close attention to any industry-specific jargon, accents, or background noise. This practical test will reveal more about a tool’s performance than any marketing copy ever could.
By aligning your specific requirements with the strengths of these powerful tools, you can unlock a new level of productivity, accessibility, and efficiency. The right software will feel less like a tool and more like an indispensable extension of your workflow, freeing you to focus on what matters most.
Ready to experience a dictation tool built for speed, accuracy, and seamless integration into your daily workflow? VoiceType AI is designed for professionals, writers, and students who need to capture their thoughts effortlessly. Try VoiceType AI today to see how fast, intuitive, and powerful voice-to-text can be.
Manually typing every email, report, and note is a significant time drain. Speech-to-text software offers a powerful solution, converting your spoken words into accurate text instantly. This frees up your time, boosts productivity, and can even make writing more accessible for those with physical limitations. But with dozens of options available, each with unique strengths and weaknesses, choosing the right tool can be overwhelming.
This guide cuts through the noise. We've analyzed the leading platforms to help you find the best speech to text software for your specific needs. Whether you're a professional dictating medical notes, a content creator transcribing interviews, or a developer integrating voice commands, this list provides a clear, practical breakdown. From everyday dictation to specialized applications, speech-to-text technology offers immense value in various sectors, including leveraging AI for transcribing police bodycam footage in legal contexts.
We will evaluate each tool based on real-world use cases, accuracy, and pricing. You'll find direct links and screenshots for every option, alongside an honest look at their pros and cons. Our goal is to equip you with the insights needed to select a voice-to-text partner that fits seamlessly into your workflow.
1. VoiceType AI
Best For: Professionals seeking maximum speed and AI-powered accuracy.
VoiceType AI establishes itself as a top-tier solution for anyone looking to dramatically accelerate their writing workflow. It isn't just a simple dictation tool; it's an AI-powered co-writer that integrates directly into any application you use, from email clients to code editors. The platform promises to make you up to nine times faster than traditional typing, a claim supported by its impressive transcription speed of 360 words per minute.
What truly sets VoiceType AI apart is its intelligent feature set, which goes far beyond basic transcription. It leverages advanced AI to provide real-time auto-formatting, context-aware tone refinement, and correction of common mistakes like misspelled names. This makes it one of the best speech to text software options for producing polished, ready-to-use text without extensive manual editing.
Key Features & Use Cases
This platform is engineered for high-stakes professional environments where clarity and efficiency are non-negotiable. Its commitment to data privacy, with all processing handled on private, encrypted servers, makes it a trusted choice for doctors, lawyers, and engineers.
Advanced AI Correction: Automatically fixes common dictation errors and adapts to your vocabulary, ensuring a high accuracy rate of 99.7%. This is ideal for medical professionals dictating complex patient notes or developers documenting intricate code.
Whisper Mode: Allows users to dictate discreetly in quiet or shared environments, such as open-plan offices or libraries, without disturbing others.
Global Accessibility: With support for over 35 languages, it's a versatile tool for international teams and multilingual professionals.
Seamless Integration: VoiceType works anywhere you can type on your laptop, eliminating the need to copy and paste from a separate window. This is perfect for drafting legal briefs in Microsoft Word or responding to customer queries in a CRM.
Pros & Cons
Pros | Cons |
|---|---|
Up to 9x faster writing with speeds of 360 wpm and 99.7% accuracy. | Subscription pricing details are general; users must visit the site for specific plans and costs. |
Advanced AI features like auto-formatting, tone adaptation, and error correction. | Extremely noisy environments might affect accuracy despite advanced noise handling. |
Supports over 35 languages and runs on private, encrypted servers, ensuring data privacy. | |
Discreet Whisper Mode allows comfortable use in shared or quiet environments. | |
Trusted by 650,000+ professionals across diverse industries, backed by strong social proof. |
Pricing: VoiceType AI offers subscription-based plans and includes a free trial to test its full capabilities. An ROI calculator on their website helps potential users quantify time and cost savings.
Website: https://voicetype.com
2. Nuance Dragon Professional
For professionals who require uncompromising accuracy and control for heavy daily dictation, Nuance Dragon Professional is the long-standing gold standard. Unlike cloud-based services, Dragon runs locally on your Windows machine, offering robust offline functionality and a high degree of customization for specialized vocabularies. This makes it a top-tier choice for legal, medical, and corporate environments where precision and data privacy are paramount.
Its core strength lies in its ability to learn your voice, accent, and specific terminology over time, achieving accuracy rates that often surpass cloud-based competitors for a single speaker. The software’s deep integration with Windows and Microsoft Office allows users to create documents, send emails, and navigate applications almost entirely by voice.
Key Features & Use Cases
Dragon excels where other tools falter: in high-stakes professional dictation. It's some of the best speech to text software available for hands-free productivity.
Custom Vocabularies & Macros: Ideal for professionals who use specific industry jargon. You can create custom commands to insert boilerplate text or perform multi-step tasks with a single voice command.
On-Device Processing: All voice recognition happens on your local machine, ensuring privacy and eliminating per-minute transcription fees.
Single-Speaker Transcription: Excellent for transcribing audio recordings of your own voice, such as dictated notes or drafts.
Best For: Professionals in specialized fields, individuals needing accessibility tools, and anyone who dictates for several hours a day. It is particularly powerful in healthcare; you can explore the use of Dragon in medical contexts to understand its specialized applications.
Pricing and Availability
Dragon Professional: A one-time purchase, typically around $699.
Availability: Windows 10/11 only. Note that Nuance’s direct web store has had intermittent pauses, so purchasing from a certified reseller is often the most reliable method.
Pros | Cons |
|---|---|
Exceptional accuracy for trained users | Windows-only platform |
Offline functionality avoids cloud fees | Not designed for multi-speaker meetings |
Deep customization for workflows | High upfront cost |
3. Amazon (marketplace category: Voice Recognition software)
While not a software tool itself, Amazon's marketplace is a critical resource for purchasing licenses, particularly for on-device software like Dragon Professional. Given that direct sales from developers can be inconsistent, Amazon provides a reliable, fast, and often competitively priced alternative for acquiring boxed or digital download versions. This makes it an essential hub for professionals who have decided on a specific local software solution.
The platform's strength lies in its vast seller network and user-centric features. Buyers can compare prices from various certified resellers, read user reviews to verify product versions, and leverage Prime shipping for quick delivery. For anyone needing to acquire some of the best speech to text software without navigating complex vendor websites, Amazon offers a streamlined and trusted purchasing experience.
Key Features & Use Cases
Amazon excels as a centralized and dependable marketplace for acquiring premium dictation software, especially when direct channels are unavailable.
Wide Selection & Seller Competition: Access multiple editions of software like Dragon from various sellers, leading to competitive pricing and frequent deals.
User Reviews and Ratings: Validate specific software versions and seller reliability by reading feedback from other professionals who have already made a purchase.
Fast & Reliable Delivery: Utilize Prime shipping for physical copies or get instant access with digital download codes, ensuring you can get started quickly.
Best For: Professionals and individuals who have chosen a specific on-premise software (like Dragon) and need a reliable, fast, and easy way to purchase it.
Pricing and Availability
Varies by Seller: Prices fluctuate based on the software version, seller, and current promotions. It is a marketplace, so costs are not fixed.
Availability: Primarily serves as a purchasing hub for Windows-based software. You can find licenses at Amazon's Voice Recognition Software category.
Pros | Cons |
|---|---|
Easy and reliable place to buy Dragon | Must carefully verify version and edition |
Competitive pricing due to multiple sellers | Some listings may feature outdated software |
Fast shipping and digital delivery options | Not a software service, but a retailer |
4. Otter.ai
For teams and individuals who need to capture, understand, and share conversations, Otter.ai has become the go-to platform for transcribing meetings. It excels at turning live or recorded audio from platforms like Zoom, Google Meet, and Microsoft Teams into searchable, shareable, and actionable notes. Its focus is less on pure dictation and more on collaborative intelligence.
Otter’s key differentiator is its AI-powered meeting assistant, which can automatically join your calendar events to record and transcribe them. During the meeting, it provides a real-time transcript where attendees can highlight key points, add comments, and assign action items, transforming a simple recording into a collaborative workspace. This makes it some of the best speech to text software for organizational productivity.
Key Features & Use Cases
Otter.ai is built to streamline meeting workflows and create a single source of truth for team conversations.
Automated Meeting Assistant: Integrates with your calendar to automatically join, record, and transcribe meetings, providing an AI-generated summary afterward.
Live Collaboration: Users can highlight text, add comments, and tag speakers in the live transcript, making it easy to capture decisions and action items.
Centralized Conversation Library: All transcripts are stored and fully searchable, creating an accessible knowledge base for your team.
Best For: Teams needing to document meetings, students recording lectures, and anyone who wants to create searchable records of multi-speaker conversations.
Pricing and Availability
Basic: Free plan with limited transcription minutes.
Pro: $16.99/month for individuals needing more minutes and features.
Business: $30/user/month, offering team features and higher usage limits.
Availability: Accessible via web and mobile apps for iOS and Android.
Pros | Cons |
|---|---|
Excellent for meetings and multi-speaker audio | Free and Pro plans have transcription minute limits |
Strong collaboration and summarization features | Highest security/compliance (HIPAA) is Enterprise-only |
Easy to use and integrates with major calendars | Accuracy can vary with heavy accents or poor audio |
5. Rev.com
For situations where absolute accuracy is non-negotiable, Rev.com offers a powerful hybrid model that combines industry-leading AI with a network of human transcriptionists. While many tools focus solely on automated solutions, Rev provides a crucial fallback for crystal-clear transcripts of complex audio, such as multi-speaker interviews, focus groups, or recordings with heavy accents and background noise.
This dual approach makes it a uniquely reliable service. Users can opt for the fast, affordable AI transcription for general use or escalate to human-powered services for final drafts, legal depositions, or broadcast-quality captions where precision is paramount. The platform’s simple, per-minute pricing structure and straightforward ordering process remove the guesswork from getting high-quality transcripts.
Key Features & Use Cases
Rev's strength lies in its guaranteed accuracy, making it some of the best speech to text software when an AI-only approach isn't enough.
Human Transcription: Its flagship service delivers 99% accuracy by using professional human transcriptionists, ideal for legal, academic, and media production.
AI Transcription & Captions: For quicker, lower-cost needs, its automated service provides a fast and reliable alternative for meeting notes or draft content.
Interactive Editor: All transcripts come with an interactive editor that syncs the audio with the text, making review and edits simple and efficient.
Best For: Podcasters, journalists, researchers, and legal professionals who need publish-ready, highly accurate transcripts and cannot risk errors from fully automated systems.
Pricing and Availability
Human Transcription: Starts at $1.50 per audio minute.
AI Transcription: Starts at $0.25 per audio minute.
Availability: Web-based platform, accessible from any device. Visit Rev.com/pricing for full details.
Pros | Cons |
|---|---|
Industry-leading 99% accuracy via humans | Human service costs can be high for bulk audio |
Simple, transparent per-minute pricing | Automated AI is less accurate than top competitors |
Fast turnaround times for both services | Not ideal for real-time dictation |
6. Descript
Descript flips the script on traditional transcription by treating audio and video as editable text. It’s an all-in-one platform built for creators, podcasters, and marketing teams who need to move seamlessly from raw recording to a polished, published product. Instead of complex timelines, you edit your media by simply deleting words or sentences in the generated transcript, making it incredibly intuitive for anyone comfortable with a word processor.
Its true innovation lies in this transcript-driven workflow. Correcting a mistranscribed word automatically corrects the audio, while features like one-click filler word removal ("um," "uh") and Studio Sound audio enhancement can save hours of tedious manual editing. This makes it some of the best speech to text software for content production.
Key Features & Use Cases
Descript excels in production workflows where the transcript is not just the output but the editing tool itself.
Text-Based Editing: Ideal for podcasters and video creators. Edit your audio/video by editing the transcript, a much faster process than using traditional timeline-based editors.
Automatic Filler Word Removal: Instantly find and delete all instances of "ums" and "ahs" to clean up audio recordings with a single click.
Screen Recording & Overdub: Perfect for tutorials, marketing videos, and corporate training. Record your screen and easily correct any spoken mistakes using an AI-generated clone of your voice.
Best For: Podcasters, YouTubers, marketers, and collaborative teams who need an integrated solution for recording, transcribing, and editing audio and video content.
Pricing and Availability
Free: Includes 1 hour of transcription per month.
Creator: $12/user/month (billed annually) for 10 hours/month.
Pro: $24/user/month (billed annually) for 30 hours/month.
Business: Custom pricing for teams needing collaboration controls.
Availability: Available on Mac and Windows. You can learn more at https://www.descript.com/pricing.
Pros | Cons |
|---|---|
Creator-friendly integrated workflow | Pricing complexity depends on usage |
Powerful text-based video/audio editing | Not ideal for simple, one-off transcription |
Excellent tools for audio cleanup | Plan changes require monitoring usage credits |
7. Sonix.ai
For content creators, researchers, and global teams who need fast, accurate transcriptions with extensive export and collaboration options, Sonix.ai stands out as a powerful automated service. It’s designed to process audio and video files quickly, turning them into editable, searchable text with speaker labeling and timestamps. The platform is entirely cloud-based, offering a streamlined workflow from upload to final export.
Its primary strength is its balance of speed, accuracy, and post-transcription tools. Sonix provides an interactive editor that synchronizes the text with the audio, allowing for easy review and correction. This focus on usability and flexible output formats makes it an excellent choice for journalists, podcasters, and video producers who need to create transcripts, captions, or subtitles efficiently.
Key Features & Use Cases
Sonix is some of the best speech to text software for teams that need to process and repurpose audio or video content without a steep learning curve.
Automated Transcription & Translation: Quickly transcribes from over 38 languages and offers an add-on service to translate the finished transcript into dozens more.
Collaborative Editor: The in-browser editor allows team members to view, edit, and comment on transcripts, streamlining the review process for projects.
Extensive Export Options: Exports transcripts into numerous formats, including Microsoft Word, TXT, PDF, and subtitle files like SRT and VTT.
Best For: Podcasters, video editors, journalists, researchers, and marketing teams needing to transcribe interviews, meetings, or media files for content creation and analysis.
Pricing and Availability
Standard (Pay-as-you-go): $10 per hour.
Premium Subscription: $5 per hour plus a $22 per user/month fee, offering more collaborative features.
Availability: Accessible via any modern web browser. Explore plans at Sonix.ai.
Pros | Cons |
|---|---|
Simple, predictable pricing | Translation and other add-ons cost extra |
Robust export formats (SRT, VTT, Word) | No human review service is offered |
Strong team collaboration features | Accuracy can vary with poor audio quality |
8. Deepgram
For developers and enterprises needing to build voice-enabled applications, Deepgram provides a high-performance, API-first speech-to-text platform. It's engineered for speed and scalability, offering real-time streaming and pre-recorded transcription models that are both fast and cost-effective. Unlike consumer-facing tools, Deepgram is a foundational layer for products that require voice data processing, from conversational AI to media transcription.
Its modern architecture is designed for developers, offering extensive documentation and powerful features like speaker diarization, PII redaction, and entity detection. With a focus on performance and low-latency streaming, Deepgram has become a go-to choice for companies building real-time voice agents, analytics platforms, and other demanding voice applications.
Key Features & Use Cases
Deepgram is some of the best speech to text software for developers who need to integrate transcription directly into their products and workflows.
Real-Time Streaming: Optimized for low latency, making it ideal for voice bots, live captioning, and conversational AI applications.
Advanced Audio Intelligence: Offers features like speaker diarization, topic detection, and PII redaction to enrich transcription data.
Developer-Focused: Provides robust SDKs, clear API documentation, and generous free credits for developers to start building.
Best For: Software developers, product teams, and enterprises building voice-enabled applications, contact center analytics solutions, or media processing pipelines. You can explore how it compares to other solutions in our review of the best AI transcription software.
Pricing and Availability
Pay-as-you-go: Highly competitive per-minute pricing that varies by model. Starts with a generous free credit tier.
Availability: Accessible globally via API. More information is available on the Deepgram pricing page.
Pros | Cons |
|---|---|
Highly competitive pricing | Purely an API, no consumer interface |
Fast real-time streaming | Requires development resources |
Excellent developer tools | Not suited for simple file uploads |
9. Google Cloud Speech-to-Text
For developers and enterprises needing to integrate high-quality, scalable voice recognition into their applications, Google Cloud Speech-to-Text provides a powerful and mature API. This service is a core component of the Google Cloud Platform, offering the same technology that powers products like Google Assistant. It excels at both real-time streaming for live applications and batch processing of large audio file archives.
Its main advantage is the flexibility and depth of its models, including specialized options for medical transcription and multi-channel audio from call centers. The API is robust, well-documented, and designed for high-volume use cases where reliability and integration with other cloud services are critical.
Key Features & Use Cases
Google’s API is some of the best speech to text software for building voice-enabled products and analyzing audio data at scale.
Standard & Medical Models: Choose from general-purpose models or a HIPAA-eligible model fine-tuned for medical terminology and doctor-patient conversations.
Speaker Diarization: Automatically identify and label different speakers in a single audio file, which is crucial for transcribing meetings or interviews.
Streaming & Batch Processing: Supports both live, real-time transcription for applications and efficient processing of large volumes of pre-recorded audio.
Best For: Developers building voice-controlled apps, businesses analyzing call center audio, and companies needing to transcribe large media archives.
Pricing and Availability
Pay-As-You-Go: Billed per minute of audio processed, with a generous free tier each month. Pricing varies by model (Standard, Medical, etc.) and offers discounts for high-volume usage.
Availability: Accessible globally via the Google Cloud Platform. Requires a Google Cloud account with billing set up. This comprehensive review of Google Cloud Speech-to-Text provides more detail on its capabilities.
Pros | Cons |
|---|---|
Highly scalable and reliable | Requires a Google Cloud account and billing setup |
Excellent integration with other Google services | Pricing can be complex to calculate |
Extensive language support | Primarily for developers, not a consumer-facing app |
10. Amazon Transcribe (AWS)
For developers and businesses building applications that require scalable, high-quality speech recognition, Amazon Transcribe is a core component of the AWS ecosystem. This cloud-based, fully managed service makes it easy to add speech-to-text capabilities to any application via an API. It's designed for high-volume, automated workflows rather than direct end-user dictation, excelling at processing large batches of audio files stored in Amazon S3 or transcribing real-time audio streams.
Its key differentiator is its deep integration with other AWS services, allowing for powerful, automated data pipelines. For instance, you can automatically transcribe customer service calls and then analyze the text for sentiment with Amazon Comprehend. This makes it some of the best speech to text software for companies already invested in the AWS platform seeking to unlock insights from audio data at scale.
Key Features & Use Cases
Amazon Transcribe is built for programmatic use, enabling everything from call center analytics to media content indexing.
Speaker Diarization & Channel Identification: Automatically identifies "who spoke when" and can process separate audio channels, making it ideal for transcribing multi-participant recordings like interviews or support calls.
PII Redaction: Can automatically detect and redact personally identifiable information (PII) from transcripts to help with compliance and privacy requirements.
Custom Vocabularies: Allows you to improve transcription accuracy for domain-specific terms, product names, or unique acronyms that are not in the standard dictionary.
Best For: Developers building voice-enabled applications, businesses needing to analyze call center recordings, and media companies looking to create searchable archives of audio/video content.
Pricing and Availability
Pay-As-You-Go: Billed per second of audio transcribed, with a free tier for new customers. Standard transcription rates are typically around $0.024 per minute. See the official AWS pricing page for details.
Availability: Accessible globally via the AWS cloud platform.
Pros | Cons |
|---|---|
Highly scalable and reliable | Not a user-facing application; requires technical expertise |
Deep integration with the AWS ecosystem | Billing can be complex with multiple AWS services involved |
Advanced features like PII redaction | Setup can be overwhelming for those new to AWS |
11. Microsoft Azure AI Speech (Speech to Text)
For organizations already embedded in the Microsoft ecosystem, Azure AI Speech provides a powerful, enterprise-grade transcription service that integrates seamlessly with other Azure services. It's a cloud-based solution designed for scalability, supporting both real-time streaming for applications like voice assistants and batch processing for transcribing large audio files. Its flexibility makes it a strong contender for developers building voice-enabled applications and businesses needing reliable, large-scale transcription.
The service's core advantage is its deep customization and deployment flexibility. Users can train custom models with domain-specific data to improve accuracy for technical jargon, unique names, or accented speech. Furthermore, its ability to be deployed in containers offers a hybrid approach, allowing businesses to run the transcription engine on-premises for enhanced data privacy and control.
Key Features & Use Cases
Azure AI Speech is some of the best speech to text software for developers and enterprises needing a scalable and customizable transcription engine.
Custom Models: Train the AI on your specific terminology, such as product names or industry-specific acronyms, to achieve higher accuracy than generic models.
Speaker Diarization: Automatically identifies and labels who is speaking in a conversation, making it ideal for transcribing meetings, interviews, or call center recordings.
Flexible Deployment: Run the service in the Azure cloud or deploy it on your own infrastructure using containers for compliance and data residency requirements.
Best For: Developers building voice-enabled products, large enterprises standardizing on Microsoft technologies, and organizations with strict data privacy or compliance needs.
Pricing and Availability
Free Tier: Includes a generous monthly quota of free audio hours.
Pay-as-you-go: Billed per audio hour, with pricing varying by feature and region. Commitment tiers are available for discounted rates.
Availability: Accessible globally via the Azure Speech Services portal.
Pros | Cons |
|---|---|
Excellent for Microsoft-centric organizations | Pricing tables can be complex to navigate |
Flexible hybrid deployment with containers | May require portal verification for exact costs |
Strong customization and scalability | Less intuitive for non-developers |
12. OpenAI Audio (Whisper API + Realtime/Audio models)
For developers and businesses seeking a powerful, scalable, and cost-effective transcription engine to build into their own applications, OpenAI's audio models are a dominant force. The platform is anchored by Whisper, a highly accurate model renowned for its performance on a diverse range of audio, accents, and background noise. It's less of a consumer-facing tool and more of a foundational technology for developers.
The introduction of real-time models like GPT-4o's audio capabilities has pushed the boundaries further, unifying speech-to-text, language processing, and text-to-speech into a single, low-latency stream. This enables the creation of highly responsive and natural-sounding conversational AI agents, moving beyond simple transcription to interactive voice experiences.
Key Features & Use Cases
OpenAI provides the building blocks for some of the best speech to text software integrations available today, from simple file processing to complex conversational AI.
Whisper API: Ideal for asynchronous transcription of audio/video files. It can handle various formats and includes robust language detection and translation capabilities.
Realtime Audio Models: Designed for interactive applications like voice assistants, real-time translation, and AI customer service agents where minimal latency is critical.
High Accuracy: The models are trained on a massive and diverse dataset, providing excellent accuracy across different languages, accents, and audio conditions without user-specific training.
Best For: Developers building voice-enabled applications, businesses needing bulk transcription for analytics, and creators integrating automated captions or subtitles into their platforms.
Pricing and Availability
Whisper API: Pay-as-you-go, priced per minute of audio processed (e.g., $0.006/minute).
Real-time/Audio-in: Priced on a token-based model, similar to their language models.
Availability: Accessible globally via the OpenAI API.
Pros | Cons |
|---|---|
Exceptional accuracy on diverse audio | Requires technical expertise (API-based) |
Very low cost-per-minute for Whisper | Fewer native tools for diarization |
Realtime models enable conversational AI | Whisper API has a 25MB file size limit |
Top 12 Speech-to-Text Software Comparison
Product | Core Features & Accuracy | User Experience & Quality ★ | Value Proposition & Pricing 💰 | Target Audience 👥 | Unique Selling Points ✨ |
|---|---|---|---|---|---|
🏆 VoiceType AI | 99.7% accuracy, 360 wpm, 35+ languages, encrypted | High accuracy, auto-formatting, tone adaption | Affordable subscriptions, ROI calculator | Professionals, marketers, doctors, journalists, execs | Whisper Mode, context-tailored text, multi-app use |
Nuance Dragon Professional | On-device Windows dictation, custom vocabularies | Very high accuracy for trained users | One-time purchase, no cloud fees | Windows professionals, accessibility users | Offline use, macros, Dragon Anywhere integration |
Amazon Voice Recognition | Marketplace for various voice software | Ratings & reviews for validation | Competitive pricing, deals | Buyers seeking Dragon and other software | Easy purchase, Prime shipping |
Otter.ai | Live transcription, calendar integration, multi-lang | Collaborative features, speaker tags | Free tier, Business plans | Teams transcribing meetings | AI Meeting Agent, automated summaries |
Rev.com | Human+AI transcription hybrid | 99% human accuracy, simple UI | Per-minute pricing, subscriptions | Projects needing accuracy & quick turnaround | Reliable human transcription, interactive editor |
Descript | Text-based audio/video editing | Creator-friendly, filler removal | Usage-based, complex pricing | Podcasters, creators, teams | Studio Sound, stock media, collaboration |
Sonix.ai | Pay-as-you-go/subscription, timestamps, translation | Predictable pricing, strong exports | Transparent plans | Global teams, batch transcription | API, custom dictionary, multiple export formats |
Deepgram | Real-time & batch transcription, developer API | Competitive pricing, strong docs | Pay-as-you-go | Developers, enterprises | PII redaction, Voice Agent API, free developer credits |
Google Cloud Speech-to-Text | Medical & standard models, speaker diarization | Mature platform, integrated with Google Cloud | Volume discounts, complex pricing | Enterprises, large volume users | Medical models, flexible APIs |
Amazon Transcribe (AWS) | Streaming & batch, vocab customization, HIPAA-eligible | Scalable, pay-as-you-go pricing | Usage-based pricing | AWS customers, enterprises | Deep AWS integration, contact center analytics |
Microsoft Azure AI Speech | Real-time & batch, custom models, containers | Flexible deployment, free quota | Complex pricing, regional variance | Microsoft/Azure based orgs | Pronunciation assessment, hybrid deployment |
OpenAI Audio (Whisper API) | Whisper API for transcription, realtime GPT-4o models | Low-cost Whisper pricing | Token-based pricing for realtime | Developers, low-latency voice app creators | Unified STT+LLM+TTS, very low per-minute cost |
Making Your Final Choice: Which Speech to Text Tool is Right for You?
Navigating the crowded market for the best speech to text software can feel overwhelming, but the right choice ultimately comes down to your specific needs and workflow. We've explored everything from polished, user-friendly applications designed for content creators and professionals to powerful, developer-focused APIs that offer unparalleled customization and scale. The key takeaway is that there is no single "best" solution for everyone; the ideal tool is the one that seamlessly integrates into your daily tasks and delivers the accuracy and features you require most.
Whether you're a journalist using Otter.ai for interview transcriptions, a developer leveraging Deepgram for real-time applications, or a medical professional relying on Nuance Dragon for clinical documentation, the perfect fit exists. Your decision hinges on a clear understanding of your primary use case.
How to Select the Right Tool for Your Needs
To make your final decision, move beyond feature lists and focus on practical application. Your evaluation should be guided by a few core questions that directly impact usability and performance in your specific environment.
What is your primary use case? Are you transcribing pre-recorded meetings (like with Rev.com or Sonix.ai), dictating content directly into documents (VoiceType AI, Dragon), or building a custom application that needs a speech recognition engine (AWS, Google Cloud, OpenAI)? Your core task dictates the type of software you need.
What level of accuracy is non-negotiable? For legal and medical fields, near-perfect accuracy with specialized vocabulary support is essential. For internal note-taking or drafting content, a slightly lower accuracy rate might be acceptable if the software offers superior speed and editing tools.
How important is real-time transcription? If you need live captions for webinars, virtual meetings, or customer support calls, prioritize tools that excel in real-time performance, such as Descript or dedicated APIs like Deepgram.
What is your technical comfort level? If you're not a developer, stick to out-of-the-box solutions with intuitive user interfaces. For those building custom software, evaluating APIs is critical. For a deeper dive into that specific area, reviewing detailed comparisons and criteria for finding the best Speech to Text API can provide the clarity needed to choose the right engine for your project.
What is your budget? Your budget will guide you toward a per-minute API pricing model, a flat-rate monthly subscription, or a one-time software purchase. Be sure to calculate the total cost based on your anticipated usage.
Your Next Steps
The journey to finding the best speech to text software for your needs ends with hands-on testing. Nearly every tool on this list offers a free trial or a free tier. Take advantage of it. Upload a sample audio file that represents your typical use case, paying close attention to any industry-specific jargon, accents, or background noise. This practical test will reveal more about a tool’s performance than any marketing copy ever could.
By aligning your specific requirements with the strengths of these powerful tools, you can unlock a new level of productivity, accessibility, and efficiency. The right software will feel less like a tool and more like an indispensable extension of your workflow, freeing you to focus on what matters most.
Ready to experience a dictation tool built for speed, accuracy, and seamless integration into your daily workflow? VoiceType AI is designed for professionals, writers, and students who need to capture their thoughts effortlessly. Try VoiceType AI today to see how fast, intuitive, and powerful voice-to-text can be.
Manually typing every email, report, and note is a significant time drain. Speech-to-text software offers a powerful solution, converting your spoken words into accurate text instantly. This frees up your time, boosts productivity, and can even make writing more accessible for those with physical limitations. But with dozens of options available, each with unique strengths and weaknesses, choosing the right tool can be overwhelming.
This guide cuts through the noise. We've analyzed the leading platforms to help you find the best speech to text software for your specific needs. Whether you're a professional dictating medical notes, a content creator transcribing interviews, or a developer integrating voice commands, this list provides a clear, practical breakdown. From everyday dictation to specialized applications, speech-to-text technology offers immense value in various sectors, including leveraging AI for transcribing police bodycam footage in legal contexts.
We will evaluate each tool based on real-world use cases, accuracy, and pricing. You'll find direct links and screenshots for every option, alongside an honest look at their pros and cons. Our goal is to equip you with the insights needed to select a voice-to-text partner that fits seamlessly into your workflow.
1. VoiceType AI
Best For: Professionals seeking maximum speed and AI-powered accuracy.
VoiceType AI establishes itself as a top-tier solution for anyone looking to dramatically accelerate their writing workflow. It isn't just a simple dictation tool; it's an AI-powered co-writer that integrates directly into any application you use, from email clients to code editors. The platform promises to make you up to nine times faster than traditional typing, a claim supported by its impressive transcription speed of 360 words per minute.
What truly sets VoiceType AI apart is its intelligent feature set, which goes far beyond basic transcription. It leverages advanced AI to provide real-time auto-formatting, context-aware tone refinement, and correction of common mistakes like misspelled names. This makes it one of the best speech to text software options for producing polished, ready-to-use text without extensive manual editing.
Key Features & Use Cases
This platform is engineered for high-stakes professional environments where clarity and efficiency are non-negotiable. Its commitment to data privacy, with all processing handled on private, encrypted servers, makes it a trusted choice for doctors, lawyers, and engineers.
Advanced AI Correction: Automatically fixes common dictation errors and adapts to your vocabulary, ensuring a high accuracy rate of 99.7%. This is ideal for medical professionals dictating complex patient notes or developers documenting intricate code.
Whisper Mode: Allows users to dictate discreetly in quiet or shared environments, such as open-plan offices or libraries, without disturbing others.
Global Accessibility: With support for over 35 languages, it's a versatile tool for international teams and multilingual professionals.
Seamless Integration: VoiceType works anywhere you can type on your laptop, eliminating the need to copy and paste from a separate window. This is perfect for drafting legal briefs in Microsoft Word or responding to customer queries in a CRM.
Pros & Cons
Pros | Cons |
|---|---|
Up to 9x faster writing with speeds of 360 wpm and 99.7% accuracy. | Subscription pricing details are general; users must visit the site for specific plans and costs. |
Advanced AI features like auto-formatting, tone adaptation, and error correction. | Extremely noisy environments might affect accuracy despite advanced noise handling. |
Supports over 35 languages and runs on private, encrypted servers, ensuring data privacy. | |
Discreet Whisper Mode allows comfortable use in shared or quiet environments. | |
Trusted by 650,000+ professionals across diverse industries, backed by strong social proof. |
Pricing: VoiceType AI offers subscription-based plans and includes a free trial to test its full capabilities. An ROI calculator on their website helps potential users quantify time and cost savings.
Website: https://voicetype.com
2. Nuance Dragon Professional
For professionals who require uncompromising accuracy and control for heavy daily dictation, Nuance Dragon Professional is the long-standing gold standard. Unlike cloud-based services, Dragon runs locally on your Windows machine, offering robust offline functionality and a high degree of customization for specialized vocabularies. This makes it a top-tier choice for legal, medical, and corporate environments where precision and data privacy are paramount.
Its core strength lies in its ability to learn your voice, accent, and specific terminology over time, achieving accuracy rates that often surpass cloud-based competitors for a single speaker. The software’s deep integration with Windows and Microsoft Office allows users to create documents, send emails, and navigate applications almost entirely by voice.
Key Features & Use Cases
Dragon excels where other tools falter: in high-stakes professional dictation. It's some of the best speech to text software available for hands-free productivity.
Custom Vocabularies & Macros: Ideal for professionals who use specific industry jargon. You can create custom commands to insert boilerplate text or perform multi-step tasks with a single voice command.
On-Device Processing: All voice recognition happens on your local machine, ensuring privacy and eliminating per-minute transcription fees.
Single-Speaker Transcription: Excellent for transcribing audio recordings of your own voice, such as dictated notes or drafts.
Best For: Professionals in specialized fields, individuals needing accessibility tools, and anyone who dictates for several hours a day. It is particularly powerful in healthcare; you can explore the use of Dragon in medical contexts to understand its specialized applications.
Pricing and Availability
Dragon Professional: A one-time purchase, typically around $699.
Availability: Windows 10/11 only. Note that Nuance’s direct web store has had intermittent pauses, so purchasing from a certified reseller is often the most reliable method.
Pros | Cons |
|---|---|
Exceptional accuracy for trained users | Windows-only platform |
Offline functionality avoids cloud fees | Not designed for multi-speaker meetings |
Deep customization for workflows | High upfront cost |
3. Amazon (marketplace category: Voice Recognition software)
While not a software tool itself, Amazon's marketplace is a critical resource for purchasing licenses, particularly for on-device software like Dragon Professional. Given that direct sales from developers can be inconsistent, Amazon provides a reliable, fast, and often competitively priced alternative for acquiring boxed or digital download versions. This makes it an essential hub for professionals who have decided on a specific local software solution.
The platform's strength lies in its vast seller network and user-centric features. Buyers can compare prices from various certified resellers, read user reviews to verify product versions, and leverage Prime shipping for quick delivery. For anyone needing to acquire some of the best speech to text software without navigating complex vendor websites, Amazon offers a streamlined and trusted purchasing experience.
Key Features & Use Cases
Amazon excels as a centralized and dependable marketplace for acquiring premium dictation software, especially when direct channels are unavailable.
Wide Selection & Seller Competition: Access multiple editions of software like Dragon from various sellers, leading to competitive pricing and frequent deals.
User Reviews and Ratings: Validate specific software versions and seller reliability by reading feedback from other professionals who have already made a purchase.
Fast & Reliable Delivery: Utilize Prime shipping for physical copies or get instant access with digital download codes, ensuring you can get started quickly.
Best For: Professionals and individuals who have chosen a specific on-premise software (like Dragon) and need a reliable, fast, and easy way to purchase it.
Pricing and Availability
Varies by Seller: Prices fluctuate based on the software version, seller, and current promotions. It is a marketplace, so costs are not fixed.
Availability: Primarily serves as a purchasing hub for Windows-based software. You can find licenses at Amazon's Voice Recognition Software category.
Pros | Cons |
|---|---|
Easy and reliable place to buy Dragon | Must carefully verify version and edition |
Competitive pricing due to multiple sellers | Some listings may feature outdated software |
Fast shipping and digital delivery options | Not a software service, but a retailer |
4. Otter.ai
For teams and individuals who need to capture, understand, and share conversations, Otter.ai has become the go-to platform for transcribing meetings. It excels at turning live or recorded audio from platforms like Zoom, Google Meet, and Microsoft Teams into searchable, shareable, and actionable notes. Its focus is less on pure dictation and more on collaborative intelligence.
Otter’s key differentiator is its AI-powered meeting assistant, which can automatically join your calendar events to record and transcribe them. During the meeting, it provides a real-time transcript where attendees can highlight key points, add comments, and assign action items, transforming a simple recording into a collaborative workspace. This makes it some of the best speech to text software for organizational productivity.
Key Features & Use Cases
Otter.ai is built to streamline meeting workflows and create a single source of truth for team conversations.
Automated Meeting Assistant: Integrates with your calendar to automatically join, record, and transcribe meetings, providing an AI-generated summary afterward.
Live Collaboration: Users can highlight text, add comments, and tag speakers in the live transcript, making it easy to capture decisions and action items.
Centralized Conversation Library: All transcripts are stored and fully searchable, creating an accessible knowledge base for your team.
Best For: Teams needing to document meetings, students recording lectures, and anyone who wants to create searchable records of multi-speaker conversations.
Pricing and Availability
Basic: Free plan with limited transcription minutes.
Pro: $16.99/month for individuals needing more minutes and features.
Business: $30/user/month, offering team features and higher usage limits.
Availability: Accessible via web and mobile apps for iOS and Android.
Pros | Cons |
|---|---|
Excellent for meetings and multi-speaker audio | Free and Pro plans have transcription minute limits |
Strong collaboration and summarization features | Highest security/compliance (HIPAA) is Enterprise-only |
Easy to use and integrates with major calendars | Accuracy can vary with heavy accents or poor audio |
5. Rev.com
For situations where absolute accuracy is non-negotiable, Rev.com offers a powerful hybrid model that combines industry-leading AI with a network of human transcriptionists. While many tools focus solely on automated solutions, Rev provides a crucial fallback for crystal-clear transcripts of complex audio, such as multi-speaker interviews, focus groups, or recordings with heavy accents and background noise.
This dual approach makes it a uniquely reliable service. Users can opt for the fast, affordable AI transcription for general use or escalate to human-powered services for final drafts, legal depositions, or broadcast-quality captions where precision is paramount. The platform’s simple, per-minute pricing structure and straightforward ordering process remove the guesswork from getting high-quality transcripts.
Key Features & Use Cases
Rev's strength lies in its guaranteed accuracy, making it some of the best speech to text software when an AI-only approach isn't enough.
Human Transcription: Its flagship service delivers 99% accuracy by using professional human transcriptionists, ideal for legal, academic, and media production.
AI Transcription & Captions: For quicker, lower-cost needs, its automated service provides a fast and reliable alternative for meeting notes or draft content.
Interactive Editor: All transcripts come with an interactive editor that syncs the audio with the text, making review and edits simple and efficient.
Best For: Podcasters, journalists, researchers, and legal professionals who need publish-ready, highly accurate transcripts and cannot risk errors from fully automated systems.
Pricing and Availability
Human Transcription: Starts at $1.50 per audio minute.
AI Transcription: Starts at $0.25 per audio minute.
Availability: Web-based platform, accessible from any device. Visit Rev.com/pricing for full details.
Pros | Cons |
|---|---|
Industry-leading 99% accuracy via humans | Human service costs can be high for bulk audio |
Simple, transparent per-minute pricing | Automated AI is less accurate than top competitors |
Fast turnaround times for both services | Not ideal for real-time dictation |
6. Descript
Descript flips the script on traditional transcription by treating audio and video as editable text. It’s an all-in-one platform built for creators, podcasters, and marketing teams who need to move seamlessly from raw recording to a polished, published product. Instead of complex timelines, you edit your media by simply deleting words or sentences in the generated transcript, making it incredibly intuitive for anyone comfortable with a word processor.
Its true innovation lies in this transcript-driven workflow. Correcting a mistranscribed word automatically corrects the audio, while features like one-click filler word removal ("um," "uh") and Studio Sound audio enhancement can save hours of tedious manual editing. This makes it some of the best speech to text software for content production.
Key Features & Use Cases
Descript excels in production workflows where the transcript is not just the output but the editing tool itself.
Text-Based Editing: Ideal for podcasters and video creators. Edit your audio/video by editing the transcript, a much faster process than using traditional timeline-based editors.
Automatic Filler Word Removal: Instantly find and delete all instances of "ums" and "ahs" to clean up audio recordings with a single click.
Screen Recording & Overdub: Perfect for tutorials, marketing videos, and corporate training. Record your screen and easily correct any spoken mistakes using an AI-generated clone of your voice.
Best For: Podcasters, YouTubers, marketers, and collaborative teams who need an integrated solution for recording, transcribing, and editing audio and video content.
Pricing and Availability
Free: Includes 1 hour of transcription per month.
Creator: $12/user/month (billed annually) for 10 hours/month.
Pro: $24/user/month (billed annually) for 30 hours/month.
Business: Custom pricing for teams needing collaboration controls.
Availability: Available on Mac and Windows. You can learn more at https://www.descript.com/pricing.
Pros | Cons |
|---|---|
Creator-friendly integrated workflow | Pricing complexity depends on usage |
Powerful text-based video/audio editing | Not ideal for simple, one-off transcription |
Excellent tools for audio cleanup | Plan changes require monitoring usage credits |
7. Sonix.ai
For content creators, researchers, and global teams who need fast, accurate transcriptions with extensive export and collaboration options, Sonix.ai stands out as a powerful automated service. It’s designed to process audio and video files quickly, turning them into editable, searchable text with speaker labeling and timestamps. The platform is entirely cloud-based, offering a streamlined workflow from upload to final export.
Its primary strength is its balance of speed, accuracy, and post-transcription tools. Sonix provides an interactive editor that synchronizes the text with the audio, allowing for easy review and correction. This focus on usability and flexible output formats makes it an excellent choice for journalists, podcasters, and video producers who need to create transcripts, captions, or subtitles efficiently.
Key Features & Use Cases
Sonix is some of the best speech to text software for teams that need to process and repurpose audio or video content without a steep learning curve.
Automated Transcription & Translation: Quickly transcribes from over 38 languages and offers an add-on service to translate the finished transcript into dozens more.
Collaborative Editor: The in-browser editor allows team members to view, edit, and comment on transcripts, streamlining the review process for projects.
Extensive Export Options: Exports transcripts into numerous formats, including Microsoft Word, TXT, PDF, and subtitle files like SRT and VTT.
Best For: Podcasters, video editors, journalists, researchers, and marketing teams needing to transcribe interviews, meetings, or media files for content creation and analysis.
Pricing and Availability
Standard (Pay-as-you-go): $10 per hour.
Premium Subscription: $5 per hour plus a $22 per user/month fee, offering more collaborative features.
Availability: Accessible via any modern web browser. Explore plans at Sonix.ai.
Pros | Cons |
|---|---|
Simple, predictable pricing | Translation and other add-ons cost extra |
Robust export formats (SRT, VTT, Word) | No human review service is offered |
Strong team collaboration features | Accuracy can vary with poor audio quality |
8. Deepgram
For developers and enterprises needing to build voice-enabled applications, Deepgram provides a high-performance, API-first speech-to-text platform. It's engineered for speed and scalability, offering real-time streaming and pre-recorded transcription models that are both fast and cost-effective. Unlike consumer-facing tools, Deepgram is a foundational layer for products that require voice data processing, from conversational AI to media transcription.
Its modern architecture is designed for developers, offering extensive documentation and powerful features like speaker diarization, PII redaction, and entity detection. With a focus on performance and low-latency streaming, Deepgram has become a go-to choice for companies building real-time voice agents, analytics platforms, and other demanding voice applications.
Key Features & Use Cases
Deepgram is some of the best speech to text software for developers who need to integrate transcription directly into their products and workflows.
Real-Time Streaming: Optimized for low latency, making it ideal for voice bots, live captioning, and conversational AI applications.
Advanced Audio Intelligence: Offers features like speaker diarization, topic detection, and PII redaction to enrich transcription data.
Developer-Focused: Provides robust SDKs, clear API documentation, and generous free credits for developers to start building.
Best For: Software developers, product teams, and enterprises building voice-enabled applications, contact center analytics solutions, or media processing pipelines. You can explore how it compares to other solutions in our review of the best AI transcription software.
Pricing and Availability
Pay-as-you-go: Highly competitive per-minute pricing that varies by model. Starts with a generous free credit tier.
Availability: Accessible globally via API. More information is available on the Deepgram pricing page.
Pros | Cons |
|---|---|
Highly competitive pricing | Purely an API, no consumer interface |
Fast real-time streaming | Requires development resources |
Excellent developer tools | Not suited for simple file uploads |
9. Google Cloud Speech-to-Text
For developers and enterprises needing to integrate high-quality, scalable voice recognition into their applications, Google Cloud Speech-to-Text provides a powerful and mature API. This service is a core component of the Google Cloud Platform, offering the same technology that powers products like Google Assistant. It excels at both real-time streaming for live applications and batch processing of large audio file archives.
Its main advantage is the flexibility and depth of its models, including specialized options for medical transcription and multi-channel audio from call centers. The API is robust, well-documented, and designed for high-volume use cases where reliability and integration with other cloud services are critical.
Key Features & Use Cases
Google’s API is some of the best speech to text software for building voice-enabled products and analyzing audio data at scale.
Standard & Medical Models: Choose from general-purpose models or a HIPAA-eligible model fine-tuned for medical terminology and doctor-patient conversations.
Speaker Diarization: Automatically identify and label different speakers in a single audio file, which is crucial for transcribing meetings or interviews.
Streaming & Batch Processing: Supports both live, real-time transcription for applications and efficient processing of large volumes of pre-recorded audio.
Best For: Developers building voice-controlled apps, businesses analyzing call center audio, and companies needing to transcribe large media archives.
Pricing and Availability
Pay-As-You-Go: Billed per minute of audio processed, with a generous free tier each month. Pricing varies by model (Standard, Medical, etc.) and offers discounts for high-volume usage.
Availability: Accessible globally via the Google Cloud Platform. Requires a Google Cloud account with billing set up. This comprehensive review of Google Cloud Speech-to-Text provides more detail on its capabilities.
Pros | Cons |
|---|---|
Highly scalable and reliable | Requires a Google Cloud account and billing setup |
Excellent integration with other Google services | Pricing can be complex to calculate |
Extensive language support | Primarily for developers, not a consumer-facing app |
10. Amazon Transcribe (AWS)
For developers and businesses building applications that require scalable, high-quality speech recognition, Amazon Transcribe is a core component of the AWS ecosystem. This cloud-based, fully managed service makes it easy to add speech-to-text capabilities to any application via an API. It's designed for high-volume, automated workflows rather than direct end-user dictation, excelling at processing large batches of audio files stored in Amazon S3 or transcribing real-time audio streams.
Its key differentiator is its deep integration with other AWS services, allowing for powerful, automated data pipelines. For instance, you can automatically transcribe customer service calls and then analyze the text for sentiment with Amazon Comprehend. This makes it some of the best speech to text software for companies already invested in the AWS platform seeking to unlock insights from audio data at scale.
Key Features & Use Cases
Amazon Transcribe is built for programmatic use, enabling everything from call center analytics to media content indexing.
Speaker Diarization & Channel Identification: Automatically identifies "who spoke when" and can process separate audio channels, making it ideal for transcribing multi-participant recordings like interviews or support calls.
PII Redaction: Can automatically detect and redact personally identifiable information (PII) from transcripts to help with compliance and privacy requirements.
Custom Vocabularies: Allows you to improve transcription accuracy for domain-specific terms, product names, or unique acronyms that are not in the standard dictionary.
Best For: Developers building voice-enabled applications, businesses needing to analyze call center recordings, and media companies looking to create searchable archives of audio/video content.
Pricing and Availability
Pay-As-You-Go: Billed per second of audio transcribed, with a free tier for new customers. Standard transcription rates are typically around $0.024 per minute. See the official AWS pricing page for details.
Availability: Accessible globally via the AWS cloud platform.
Pros | Cons |
|---|---|
Highly scalable and reliable | Not a user-facing application; requires technical expertise |
Deep integration with the AWS ecosystem | Billing can be complex with multiple AWS services involved |
Advanced features like PII redaction | Setup can be overwhelming for those new to AWS |
11. Microsoft Azure AI Speech (Speech to Text)
For organizations already embedded in the Microsoft ecosystem, Azure AI Speech provides a powerful, enterprise-grade transcription service that integrates seamlessly with other Azure services. It's a cloud-based solution designed for scalability, supporting both real-time streaming for applications like voice assistants and batch processing for transcribing large audio files. Its flexibility makes it a strong contender for developers building voice-enabled applications and businesses needing reliable, large-scale transcription.
The service's core advantage is its deep customization and deployment flexibility. Users can train custom models with domain-specific data to improve accuracy for technical jargon, unique names, or accented speech. Furthermore, its ability to be deployed in containers offers a hybrid approach, allowing businesses to run the transcription engine on-premises for enhanced data privacy and control.
Key Features & Use Cases
Azure AI Speech is some of the best speech to text software for developers and enterprises needing a scalable and customizable transcription engine.
Custom Models: Train the AI on your specific terminology, such as product names or industry-specific acronyms, to achieve higher accuracy than generic models.
Speaker Diarization: Automatically identifies and labels who is speaking in a conversation, making it ideal for transcribing meetings, interviews, or call center recordings.
Flexible Deployment: Run the service in the Azure cloud or deploy it on your own infrastructure using containers for compliance and data residency requirements.
Best For: Developers building voice-enabled products, large enterprises standardizing on Microsoft technologies, and organizations with strict data privacy or compliance needs.
Pricing and Availability
Free Tier: Includes a generous monthly quota of free audio hours.
Pay-as-you-go: Billed per audio hour, with pricing varying by feature and region. Commitment tiers are available for discounted rates.
Availability: Accessible globally via the Azure Speech Services portal.
Pros | Cons |
|---|---|
Excellent for Microsoft-centric organizations | Pricing tables can be complex to navigate |
Flexible hybrid deployment with containers | May require portal verification for exact costs |
Strong customization and scalability | Less intuitive for non-developers |
12. OpenAI Audio (Whisper API + Realtime/Audio models)
For developers and businesses seeking a powerful, scalable, and cost-effective transcription engine to build into their own applications, OpenAI's audio models are a dominant force. The platform is anchored by Whisper, a highly accurate model renowned for its performance on a diverse range of audio, accents, and background noise. It's less of a consumer-facing tool and more of a foundational technology for developers.
The introduction of real-time models like GPT-4o's audio capabilities has pushed the boundaries further, unifying speech-to-text, language processing, and text-to-speech into a single, low-latency stream. This enables the creation of highly responsive and natural-sounding conversational AI agents, moving beyond simple transcription to interactive voice experiences.
Key Features & Use Cases
OpenAI provides the building blocks for some of the best speech to text software integrations available today, from simple file processing to complex conversational AI.
Whisper API: Ideal for asynchronous transcription of audio/video files. It can handle various formats and includes robust language detection and translation capabilities.
Realtime Audio Models: Designed for interactive applications like voice assistants, real-time translation, and AI customer service agents where minimal latency is critical.
High Accuracy: The models are trained on a massive and diverse dataset, providing excellent accuracy across different languages, accents, and audio conditions without user-specific training.
Best For: Developers building voice-enabled applications, businesses needing bulk transcription for analytics, and creators integrating automated captions or subtitles into their platforms.
Pricing and Availability
Whisper API: Pay-as-you-go, priced per minute of audio processed (e.g., $0.006/minute).
Real-time/Audio-in: Priced on a token-based model, similar to their language models.
Availability: Accessible globally via the OpenAI API.
Pros | Cons |
|---|---|
Exceptional accuracy on diverse audio | Requires technical expertise (API-based) |
Very low cost-per-minute for Whisper | Fewer native tools for diarization |
Realtime models enable conversational AI | Whisper API has a 25MB file size limit |
Top 12 Speech-to-Text Software Comparison
Product | Core Features & Accuracy | User Experience & Quality ★ | Value Proposition & Pricing 💰 | Target Audience 👥 | Unique Selling Points ✨ |
|---|---|---|---|---|---|
🏆 VoiceType AI | 99.7% accuracy, 360 wpm, 35+ languages, encrypted | High accuracy, auto-formatting, tone adaption | Affordable subscriptions, ROI calculator | Professionals, marketers, doctors, journalists, execs | Whisper Mode, context-tailored text, multi-app use |
Nuance Dragon Professional | On-device Windows dictation, custom vocabularies | Very high accuracy for trained users | One-time purchase, no cloud fees | Windows professionals, accessibility users | Offline use, macros, Dragon Anywhere integration |
Amazon Voice Recognition | Marketplace for various voice software | Ratings & reviews for validation | Competitive pricing, deals | Buyers seeking Dragon and other software | Easy purchase, Prime shipping |
Otter.ai | Live transcription, calendar integration, multi-lang | Collaborative features, speaker tags | Free tier, Business plans | Teams transcribing meetings | AI Meeting Agent, automated summaries |
Rev.com | Human+AI transcription hybrid | 99% human accuracy, simple UI | Per-minute pricing, subscriptions | Projects needing accuracy & quick turnaround | Reliable human transcription, interactive editor |
Descript | Text-based audio/video editing | Creator-friendly, filler removal | Usage-based, complex pricing | Podcasters, creators, teams | Studio Sound, stock media, collaboration |
Sonix.ai | Pay-as-you-go/subscription, timestamps, translation | Predictable pricing, strong exports | Transparent plans | Global teams, batch transcription | API, custom dictionary, multiple export formats |
Deepgram | Real-time & batch transcription, developer API | Competitive pricing, strong docs | Pay-as-you-go | Developers, enterprises | PII redaction, Voice Agent API, free developer credits |
Google Cloud Speech-to-Text | Medical & standard models, speaker diarization | Mature platform, integrated with Google Cloud | Volume discounts, complex pricing | Enterprises, large volume users | Medical models, flexible APIs |
Amazon Transcribe (AWS) | Streaming & batch, vocab customization, HIPAA-eligible | Scalable, pay-as-you-go pricing | Usage-based pricing | AWS customers, enterprises | Deep AWS integration, contact center analytics |
Microsoft Azure AI Speech | Real-time & batch, custom models, containers | Flexible deployment, free quota | Complex pricing, regional variance | Microsoft/Azure based orgs | Pronunciation assessment, hybrid deployment |
OpenAI Audio (Whisper API) | Whisper API for transcription, realtime GPT-4o models | Low-cost Whisper pricing | Token-based pricing for realtime | Developers, low-latency voice app creators | Unified STT+LLM+TTS, very low per-minute cost |
Making Your Final Choice: Which Speech to Text Tool is Right for You?
Navigating the crowded market for the best speech to text software can feel overwhelming, but the right choice ultimately comes down to your specific needs and workflow. We've explored everything from polished, user-friendly applications designed for content creators and professionals to powerful, developer-focused APIs that offer unparalleled customization and scale. The key takeaway is that there is no single "best" solution for everyone; the ideal tool is the one that seamlessly integrates into your daily tasks and delivers the accuracy and features you require most.
Whether you're a journalist using Otter.ai for interview transcriptions, a developer leveraging Deepgram for real-time applications, or a medical professional relying on Nuance Dragon for clinical documentation, the perfect fit exists. Your decision hinges on a clear understanding of your primary use case.
How to Select the Right Tool for Your Needs
To make your final decision, move beyond feature lists and focus on practical application. Your evaluation should be guided by a few core questions that directly impact usability and performance in your specific environment.
What is your primary use case? Are you transcribing pre-recorded meetings (like with Rev.com or Sonix.ai), dictating content directly into documents (VoiceType AI, Dragon), or building a custom application that needs a speech recognition engine (AWS, Google Cloud, OpenAI)? Your core task dictates the type of software you need.
What level of accuracy is non-negotiable? For legal and medical fields, near-perfect accuracy with specialized vocabulary support is essential. For internal note-taking or drafting content, a slightly lower accuracy rate might be acceptable if the software offers superior speed and editing tools.
How important is real-time transcription? If you need live captions for webinars, virtual meetings, or customer support calls, prioritize tools that excel in real-time performance, such as Descript or dedicated APIs like Deepgram.
What is your technical comfort level? If you're not a developer, stick to out-of-the-box solutions with intuitive user interfaces. For those building custom software, evaluating APIs is critical. For a deeper dive into that specific area, reviewing detailed comparisons and criteria for finding the best Speech to Text API can provide the clarity needed to choose the right engine for your project.
What is your budget? Your budget will guide you toward a per-minute API pricing model, a flat-rate monthly subscription, or a one-time software purchase. Be sure to calculate the total cost based on your anticipated usage.
Your Next Steps
The journey to finding the best speech to text software for your needs ends with hands-on testing. Nearly every tool on this list offers a free trial or a free tier. Take advantage of it. Upload a sample audio file that represents your typical use case, paying close attention to any industry-specific jargon, accents, or background noise. This practical test will reveal more about a tool’s performance than any marketing copy ever could.
By aligning your specific requirements with the strengths of these powerful tools, you can unlock a new level of productivity, accessibility, and efficiency. The right software will feel less like a tool and more like an indispensable extension of your workflow, freeing you to focus on what matters most.
Ready to experience a dictation tool built for speed, accuracy, and seamless integration into your daily workflow? VoiceType AI is designed for professionals, writers, and students who need to capture their thoughts effortlessly. Try VoiceType AI today to see how fast, intuitive, and powerful voice-to-text can be.
